
-
Manage your Success Plans and Engagements, gain key insights into your implementation journey, and collaborate with your CSMsSuccessAccelerate your Purchase to Value by engaging with Informatica for Customer SuccessAll your Engagements at one place
-
A collaborative platform to connect and grow with like-minded Informaticans across the globeCommunitiesConnect and collaborate with Informatica experts and championsHave a question? Start a Discussion and get immediate answers you are looking forCustomer-organized groups that meet online and in-person. Join today to network, share ideas, and get tips on how to get the most out of Informatica
-
Troubleshooting documents, product guides, how to videos, best practices, and moreKnowledge CenterOne-stop self-service portal for solutions, FAQs, Whitepapers, How Tos, Videos, and moreVideo channel for step-by-step instructions to use our products, best practices, troubleshooting tips, and much moreInformation library of the latest product documents
-
Rich resources to help you leverage full capabilities of our productsLearnRole-based training programs for the best ROIGet certified on Informatica products. Free, Foundation, or ProfessionalFree and unlimited modules based on your expertise level and journeySelf-guided, intuitive experience platform for outcome-focused product capabilities and use cases
-
Library of content to help you leverage the best of Informatica productsResourcesMost popular webinars on product architecture, best practices, and moreProduct Availability Matrix statements of Informatica productsMonthly support newsletterInformatica Support Guide and Statements, Quick Start Guides, and Cloud Product Description ScheduleEnd of Life statements of Informatica productsMonitor the status of your Informatica services across regions
- Velocity
- Strategy
-
Solutions
- Stages
-
More
-
Manage your Success Plans and Engagements, gain key insights into your implementation journey, and collaborate with your CSMsManage your Success Plans and Engagements, gain key insights into your implementation journey, and collaborate with your CSMsAccelerate your Purchase to Value by engaging with Informatica for Customer SuccessAll your Engagements at one place
-
A collaborative platform to connect and grow with like-minded Informaticans across the globeA collaborative platform to connect and grow with like-minded Informaticans across the globeConnect and collaborate with Informatica experts and championsHave a question? Start a Discussion and get immediate answers you are looking forCustomer-organized groups that meet online and in-person. Join today to network, share ideas, and get tips on how to get the most out of Informatica
-
Troubleshooting documents, product guides, how to videos, best practices, and moreTroubleshooting documents, product guides, how to videos, best practices, and moreOne-stop self-service portal for solutions, FAQs, Whitepapers, How Tos, Videos, and moreVideo channel for step-by-step instructions to use our products, best practices, troubleshooting tips, and much moreInformation library of the latest product documents
-
Rich resources to help you leverage full capabilities of our productsRich resources to help you leverage full capabilities of our productsRole-based training programs for the best ROIGet certified on Informatica products. Free, Foundation, or ProfessionalFree and unlimited modules based on your expertise level and journeySelf-guided, intuitive experience platform for outcome-focused product capabilities and use cases
-
Library of content to help you leverage the best of Informatica productsLibrary of content to help you leverage the best of Informatica productsMost popular webinars on product architecture, best practices, and moreProduct Availability Matrix statements of Informatica productsMonthly support newsletterInformatica Support Guide and Statements, Quick Start Guides, and Cloud Product Description ScheduleEnd of Life statements of Informatica productsMonitor the status of your Informatica services across regions
-
Effective Data Standardizing Techniques
Data Governance & Privacy
Challenge
To enable users to streamline their profiling, data cleansing, and standardization processes with Informatica Data Quality 9. The intent is to shorten development timelines and ensure a consistent and methodological approach to profiling, cleansing, and standardizing project data.
Description
Data cleansing refers to operations that remove non-relevant information and noise from the content of the data. This includes the removal of errors and inconsistencies that can often be found during the course of conducting data profiling. Examples of cleansing operations include the removal of care of information (from a name field), excess character spaces, and replacing typed text with other instances of typed text. Standardization on an existing street address can be conducted. For instance, there may be situations where the column representing the street address contains the suffix strings of "GARDN", "GRDEN", or "GRDN". All instances of these suffix strings can be replaced with GDN.
Data standardization refers to operations related to modifying the appearance of the data, so that it takes on a more uniform structure and to enriching the data by deriving additional details from existing content.
Cleansing and Standardization Operations
Data can be transformed into a standard format appropriate for its business type. This is typically performed on complex data types such as name and address or product data. A data standardization operation is typically preceded with the key step of Profiling the data. The purpose of Profiling is to reveal the existing content and structure of the data. This helps to facilitate in formulating a project plan that may involve the process of standardization.
For best results, the Data Quality Developer should carry out these steps in consultation with a member of the business. Often, this individual is the data steward, the person who best understands the nature and use of the data within the business.
Using the Developer tool within IDQ, allows the developer to make use of the Standardizer transformation, which can be used for standardizing text data (optionally using reference tables). This can be accomplished by replacing strings that match reference table entries with chosen text, or with values from the Valid Column in the reference table. Multiple search and replace actions, called operations, can also be conducted in an effort to achieve the goal of standardizing the data. It is important to note the order in which the operations are performed because each preceded operation provides data to be processed by the next, and may standardize those results.
Once acceptable standardization has been achieved, a data quality scorecard can be used to measure the data quality. For information on creating a Score Card, see the Scorecards chapter of the Informatica Developer User Guide.
Discovering Business Rules
During the course of the analysis phase, the business user may discover and define business rules applicable to the data. These rules should be documented and converted to logic that can be contained within a data quality mapping. When building a data quality mapping, be sure to group related business rules together in a single Expression transformation whenever possible; otherwise the data quality mapping may become very difficult to read. If there are rules that do not lend themselves easily to regular transformations, it may be necessary to perform some custom scripting using the Java transformation. This requirement may arise when a string or an element within a string needs to be treated as an array.
Standard and Third-Party Reference Data
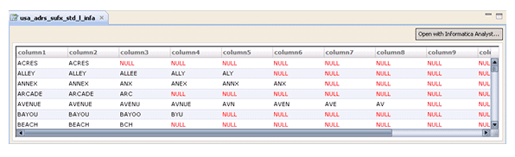
Reference data can be a useful tool when standardizing data. Terms with variant formats or spellings can be standardized to a single form. Content including General Reference Data is typically installed with IDQ as data tables to the Model Repository and Staging database. These data tables contain information on common business terms from multiple countries, which include telephone area codes, postcode formats, first names, Social Security number formats, occupations and acronyms. The illustration below shows part of a Reference data table containing address suffixes.
Common Issues when Cleansing and Standardizing Data
If there are expectations of a bureau-style service, it may be advisable to re-emphasize the score-carding approach to cleansing and standardizing. This helps to ensure that the data consumers develop reasonable expectations of what can be achieved with the data set within an agreed-upon timeframe.
Standardizing Ambiguous Data
Data values can often appear ambiguous, particularly in name and address data where name, address, and premise values can be interchangeable. For example, Hill, Park, and Church are all common surnames. In some cases, the position of the value is important. ST can be a suffix for street or a prefix for Saint, and sometimes they can both occur in the same string.
The address string St Patricks Church, Main St can reasonably be interpreted as Saint Patricks Church, Main Street. In this case, if the delimiter is a space (thus ignoring any commas and periods), the string has five tokens. Business rules may need to be written using the IDQ Java transformation, as the string is being treated as an array. St with position 1 within the string would be standardized to meaning_1, whereas St with position 5 would be standardized to meaning_2. Each data value can then be compared to a discrete prefix and suffix reference data table.
Conclusion
Using the profiling, data cleansing, and standardization techniques described in this Best Practice can help an organization to recognize the value of incorporating IDQ into their development methodology. The results produced by IDQ will be affected by the starting condition of the data and the requirements of the business users. Because data quality is an iterative process, the business rules initially developed may require ongoing modification.
When data arrives in multiple languages, it is worth creating similar pipelines within an IDQ mapping for each country and applying the same rule in each pipleline contained inside of the mapping. The data would typically be staged in a database, and the router condition could be set to country_code= DE for example, to properly direct rows of data. Countries are often identifiable by country codes which facilitate such an approach. Remember that IDQ typically installs with a large set of reference data tables and additional content is available from Informatica.
IDQ provides several transformations that focus on verifying and correcting the accuracy of name and postal address data. These transformations leverage address reference data that originates from national postal carriers such as the United States Postal Service. Such datasets enable IDQ to validate an address to premise level. Please note, the reference datasets are licensed and installed as discrete Informatica products, and thus it is important to discuss their inclusion in the project with the business in advance so as to avoid budget and installation issues. Several types of reference data, with differing levels of address granularity, are available from Informatica. Pricing for the licensing of these components may vary and should be discussed with the Informatica Account Manager.