
-
Manage your Success Plans and Engagements, gain key insights into your implementation journey, and collaborate with your CSMsSuccessAccelerate your Purchase to Value by engaging with Informatica for Customer SuccessAll your Engagements at one place
-
A collaborative platform to connect and grow with like-minded Informaticans across the globeCommunitiesConnect and collaborate with Informatica experts and championsHave a question? Start a Discussion and get immediate answers you are looking forCustomer-organized groups that meet online and in-person. Join today to network, share ideas, and get tips on how to get the most out of Informatica
-
Troubleshooting documents, product guides, how to videos, best practices, and moreKnowledge CenterOne-stop self-service portal for solutions, FAQs, Whitepapers, How Tos, Videos, and moreVideo channel for step-by-step instructions to use our products, best practices, troubleshooting tips, and much moreInformation library of the latest product documents
-
Rich resources to help you leverage full capabilities of our productsLearnRole-based training programs for the best ROIGet certified on Informatica products. Free, Foundation, or ProfessionalFree and unlimited modules based on your expertise level and journeySelf-guided, intuitive experience platform for outcome-focused product capabilities and use cases
-
Library of content to help you leverage the best of Informatica productsResourcesMost popular webinars on product architecture, best practices, and moreProduct Availability Matrix statements of Informatica productsMonthly support newsletterInformatica Support Guide and Statements, Quick Start Guides, and Cloud Product Description ScheduleEnd of Life statements of Informatica productsMonitor the status of your Informatica services across regions
- Velocity
- Strategy
-
Solutions
- Stages
-
More
-
Manage your Success Plans and Engagements, gain key insights into your implementation journey, and collaborate with your CSMsManage your Success Plans and Engagements, gain key insights into your implementation journey, and collaborate with your CSMsAccelerate your Purchase to Value by engaging with Informatica for Customer SuccessAll your Engagements at one place
-
A collaborative platform to connect and grow with like-minded Informaticans across the globeA collaborative platform to connect and grow with like-minded Informaticans across the globeConnect and collaborate with Informatica experts and championsHave a question? Start a Discussion and get immediate answers you are looking forCustomer-organized groups that meet online and in-person. Join today to network, share ideas, and get tips on how to get the most out of Informatica
-
Troubleshooting documents, product guides, how to videos, best practices, and moreTroubleshooting documents, product guides, how to videos, best practices, and moreOne-stop self-service portal for solutions, FAQs, Whitepapers, How Tos, Videos, and moreVideo channel for step-by-step instructions to use our products, best practices, troubleshooting tips, and much moreInformation library of the latest product documents
-
Rich resources to help you leverage full capabilities of our productsRich resources to help you leverage full capabilities of our productsRole-based training programs for the best ROIGet certified on Informatica products. Free, Foundation, or ProfessionalFree and unlimited modules based on your expertise level and journeySelf-guided, intuitive experience platform for outcome-focused product capabilities and use cases
-
Library of content to help you leverage the best of Informatica productsLibrary of content to help you leverage the best of Informatica productsMost popular webinars on product architecture, best practices, and moreProduct Availability Matrix statements of Informatica productsMonthly support newsletterInformatica Support Guide and Statements, Quick Start Guides, and Cloud Product Description ScheduleEnd of Life statements of Informatica productsMonitor the status of your Informatica services across regions
-
Analytics Modernization
Solutions
Business Problem
Data landscapes are changing constantly, and data variety and volumes continue to rapidly expand. Companies have ambitious plans to expand and disrupt markets based on data. Business users want answers to many complex business questions. With the proliferation of data sources, and especially unstructured data such as social data, cloud-based applications, web logs, and IoT -- as well as the growing pace of business, a systematic and repeatable approach to data management for self-service analytics and experimentation – it’s more important than ever. However, finding the right data is not a trivial task.
No matter how modern your modern analytics platform is, unless your business users can find, trust, understand the context of, and quickly leverage their data assets throughout the enterprise, your analytics modernization initiative will probably deliver underwhelming results.
The Journey
Let’s explore how to embark on an Analytics Modernization journey. There are several paths one can take. While the steps are the same - establishing an enterprise-wide Data Catalog, building a Data Lake, ensuring governance across the lake, and ultimately providing access to enable self-service analytics to business users and domain experts – the sequence of these steps can vary based on customer specific situations.
When starting from scratch, prioritize the Data Catalog as the cornerstone anchoring your solution. By making the catalog the first step on your journey, the IT team and the business can start collaborating right away and all IT efforts will be guided by ultimately driving business value. The Data Catalog should be used to explore the disparate data sources and IT can align with the business on what to ingest to the Data Lake. After the ingestion phase, the Catalog should scan the newly created objects in the lake to establish effective lineage and relationship diagrams.
However, you might already have a Data Lake in place or in the works. This is a perfectly valid approach as the lake provides value for many different use cases. Your next stop should be to implement the Data Catalog. Ultimately, this will give you an enterprise view of your data which will also include the lake.
Current State:
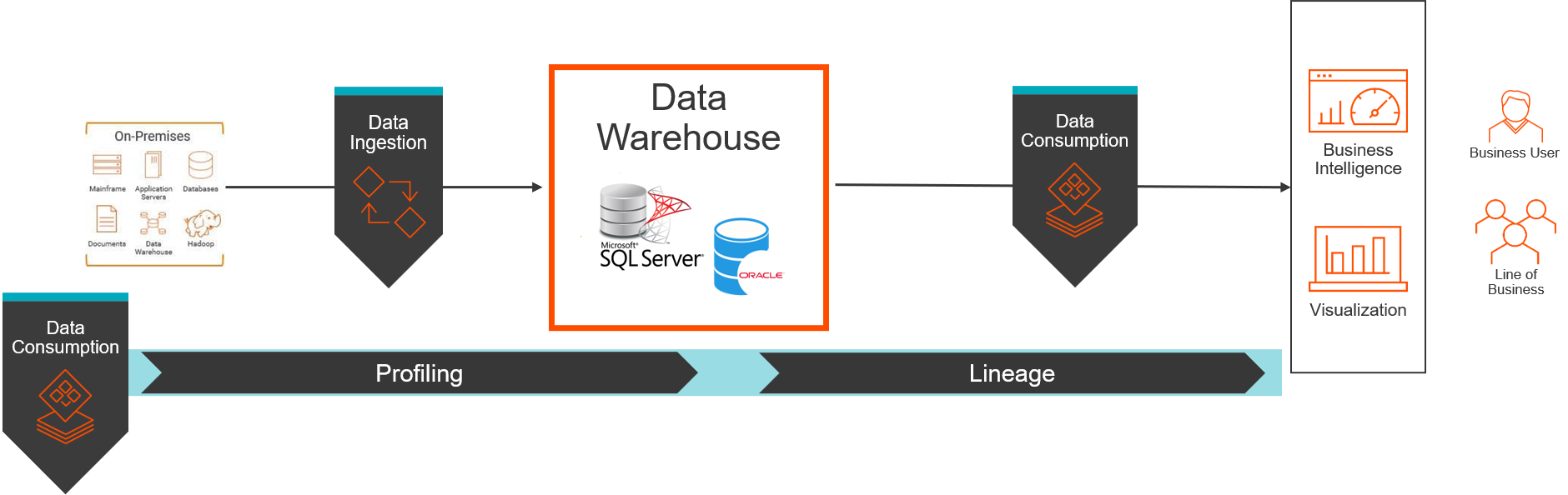
Future State:
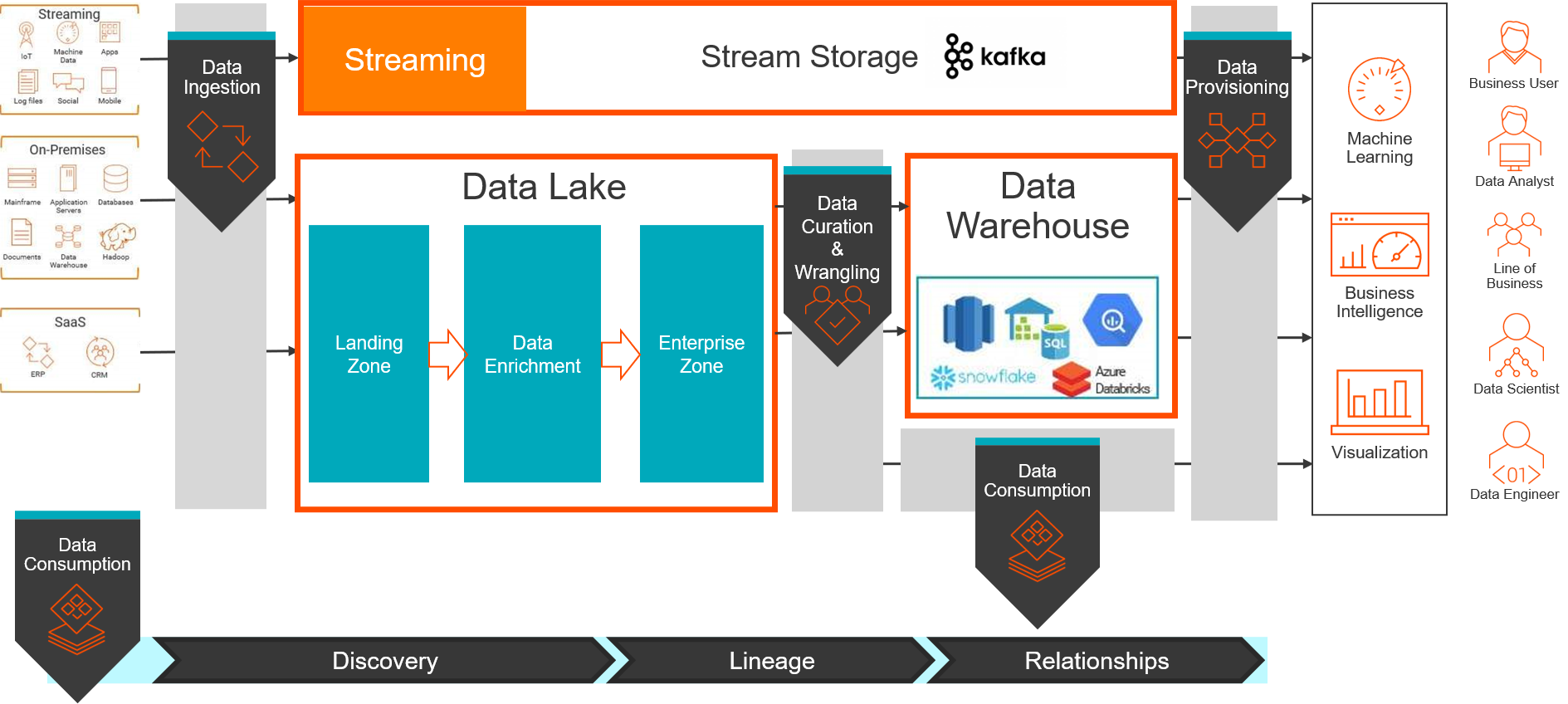
Data Catalog
Self-service analytics empowers line-of-business users and domain experts in organizations to make better decisions by autonomously unleashing the power of data. While that sounds like a straightforward concept, one of the biggest challenges is finding the right data. Companies are dealing with rapidly growing data sources, increased data complexity, applications moving to the cloud, and analytics now incorporating machine learning and AI.
For a modern self-service analytics experience, business users need to seamlessly discover and understand all relevant and trusted data and metadata across the enterprise, eliminating hidden data silos. Informatica’s Enterprise Data Catalog (EDC) is designed to meet this need. Make this the first step on your journey so IT and the business start collaborating right away.
By evaluating the data sets across the enterprise, and even profiling the data sets, IT and the business can jointly prioritize the data that needs to be loaded to a Data Lake.
Data Lake
A Data Lake enables organizations to store all structured and unstructured data efficiently, cost-effectively, and at any scale. In addition to storing relational data from line-of-business and transactional applications, a Data Lake can store unstructured and real-time data from mobile apps, IoT devices, sensors, and social media.
Data Preparation
Once the Data Lake has been established, you now have access to enterprise data without having to define the schema at the time of storage. Data discovery can be done using raw data where the analysts can experiment to find patterns that are beneficial to the business. This is suitable to determine predictive patterns and gain insight into what will happen in the future. The Informatica Enterprise Data Catalog (EDC) plays an integral role in this space, enabling business users and data analysts the ability to explore, profile, and transform data dynamically and in an interactive way.
The Data Ops teams, including data scientists, data engineers, and data analysts, can use the AI-powered Informatica EDC to easily find the data they have with a Google-like semantic search. With Informatica EDC, teams can understand key attributes about the datasets, including business context and relevancy, and determine whether the data is certified, whether it comes from trusted sources, who owns the datasets, and obtain a holistic relationship view with end-to-end data lineage and impact analysis. Additionally, an automated machine learning-based discovery process transforms related data assets into intelligent recommendations that may be of interest to users. This greatly increases confidence and reduces duplicate datasets from being created for similar projects. Moreover, to drive greater efficiencies and overcome data silos, advanced social curation and data collaboration capabilities enable DataOps teams to easily share, collaborate on, review, rate, and follow the datasets that are of interest to them.
Table of Contents
RESOURCES
Cloud Datawarehouse & Data Lake
PLAN
IMPLEMENT
MONITOR
OPTIMIZE