
-
Manage your Success Plans and Engagements, gain key insights into your implementation journey, and collaborate with your CSMsSuccessAccelerate your Purchase to Value by engaging with Informatica for Customer SuccessAll your Engagements at one place
-
A collaborative platform to connect and grow with like-minded Informaticans across the globeCommunitiesConnect and collaborate with Informatica experts and championsHave a question? Start a Discussion and get immediate answers you are looking forCustomer-organized groups that meet online and in-person. Join today to network, share ideas, and get tips on how to get the most out of Informatica
-
Troubleshooting documents, product guides, how to videos, best practices, and moreKnowledge CenterOne-stop self-service portal for solutions, FAQs, Whitepapers, How Tos, Videos, and moreVideo channel for step-by-step instructions to use our products, best practices, troubleshooting tips, and much moreInformation library of the latest product documents
-
Rich resources to help you leverage full capabilities of our productsLearnRole-based training programs for the best ROIGet certified on Informatica products. Free, Foundation, or ProfessionalFree and unlimited modules based on your expertise level and journeySelf-guided, intuitive experience platform for outcome-focused product capabilities and use cases
-
Library of content to help you leverage the best of Informatica productsResourcesMost popular webinars on product architecture, best practices, and moreProduct Availability Matrix statements of Informatica productsMonthly support newsletterInformatica Support Guide and Statements, Quick Start Guides, and Cloud Product Description ScheduleEnd of Life statements of Informatica productsMonitor the status of your Informatica services across regions
- Velocity
- Strategy
-
Solutions
- Stages
-
More
-
Manage your Success Plans and Engagements, gain key insights into your implementation journey, and collaborate with your CSMsManage your Success Plans and Engagements, gain key insights into your implementation journey, and collaborate with your CSMsAccelerate your Purchase to Value by engaging with Informatica for Customer SuccessAll your Engagements at one place
-
A collaborative platform to connect and grow with like-minded Informaticans across the globeA collaborative platform to connect and grow with like-minded Informaticans across the globeConnect and collaborate with Informatica experts and championsHave a question? Start a Discussion and get immediate answers you are looking forCustomer-organized groups that meet online and in-person. Join today to network, share ideas, and get tips on how to get the most out of Informatica
-
Troubleshooting documents, product guides, how to videos, best practices, and moreTroubleshooting documents, product guides, how to videos, best practices, and moreOne-stop self-service portal for solutions, FAQs, Whitepapers, How Tos, Videos, and moreVideo channel for step-by-step instructions to use our products, best practices, troubleshooting tips, and much moreInformation library of the latest product documents
-
Rich resources to help you leverage full capabilities of our productsRich resources to help you leverage full capabilities of our productsRole-based training programs for the best ROIGet certified on Informatica products. Free, Foundation, or ProfessionalFree and unlimited modules based on your expertise level and journeySelf-guided, intuitive experience platform for outcome-focused product capabilities and use cases
-
Library of content to help you leverage the best of Informatica productsLibrary of content to help you leverage the best of Informatica productsMost popular webinars on product architecture, best practices, and moreProduct Availability Matrix statements of Informatica productsMonthly support newsletterInformatica Support Guide and Statements, Quick Start Guides, and Cloud Product Description ScheduleEnd of Life statements of Informatica productsMonitor the status of your Informatica services across regions
-
Data Catalog & Metadata Management
Solutions
Introduction
To remain competitive in the digital economy, a data-driven company must provide business and technical users with the ability to efficiently locate, classify, assess, and interact with relevant and trusted data assets
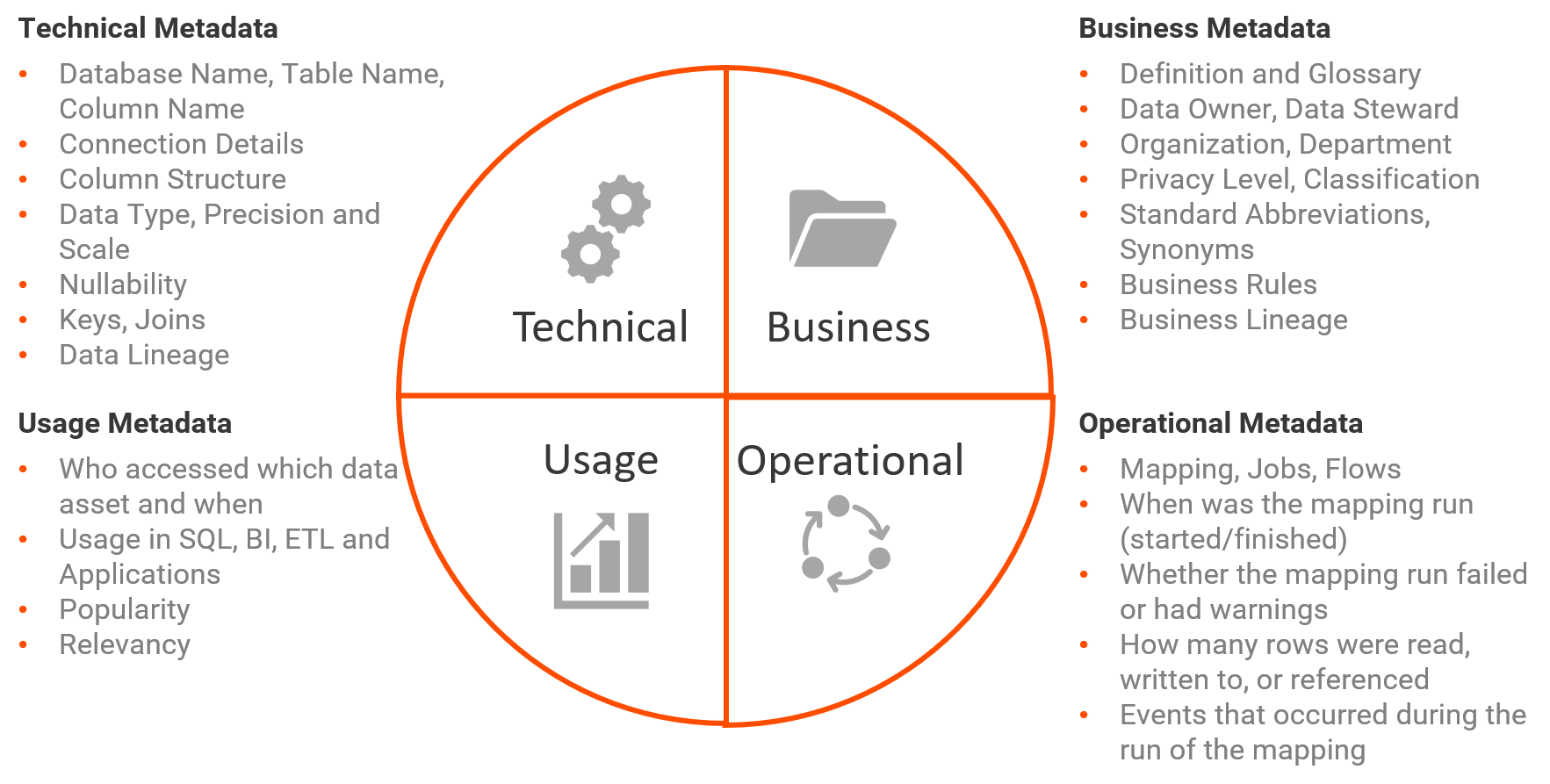
This valuable information typically resides in a broad range of on-premise and cloud-based systems and applications. Contained within these sources are four types of metadata that can be used to address a broad range of end-user needs across an organization. These metadata types are:
- Technical - Metadata generated by technical assets
- Business - Metadata generated by business processes and documentation
- Usage - Metadata generated by audit trails and privacy policies
- Operational - Metadata generated by operational schedules and code execution statistics
Examples of the information captured by each type are shown in the diagram below.
Challenges
While each system’s metadata has value as a stand-alone data resource, the information available is limited in scope to that specific application and oftentimes requires additional data assets to solve a business problem.
The challenge lies in reducing the manual, time-intensive work required to identify, evaluate, access, and organize this information in order to provide answers to questions such as:
- Which data assets are related to the issue the user is trying to address?
- Where are the identified assets located?
- Who owns the resources for granting access or providing information?
- What is the quality of the data?
What is a Data Catalog?
A data catalog solution provides a user-friendly, searchable inventory of metadata designed to classify, organize, relate, and enrich data assets across an organization to maximize data value and reuse.
Informatica’s Enterprise Data Catalog provides Data Analysts and IT users with an AI-assisted solution that offers powerful semantic search and dynamic facets to filter search results, develop data lineage, profile data statistics, derive data quality scorecards, and present holistic relationship views and data similarity recommendations supported by an integrated business glossary.
Who Benefits from the Catalog?
The array of information in a data catalog enables a broad group of end users to simplify their day-to-day job functions. The data catalog community is comprised of, but not limited to:
- Data Analysts
To search, discover, understand, and find data assets for analytics - Data Scientists
To understand impact to analytical models due to data structure, content, and value changes - Business Data Stewards
To curate, certify data assets, analyze data lineage, and track key data elements for compliance - Technical Data Stewards
To provide technical expertise around source systems, data integration, business intelligence tools or other assets - Data Architects
To manage data assets, comprehend data transformations, and assess change impact - Subject Matter Experts
To provide the knowledge and expertise in a specific subject or business area - General data community
To use as a general research tool (e.g., Developers, QA analyst, and others)
Set the Foundation
The steps required to implement a data catalog begin after the Program Strategy and Initial Use Case have been defined.
- The Program Strategy identifies potential business drivers and impact in alignment with corporate vision, addresses pain points, and delivers and communicates business impact through high-value use cases linked to business drivers.
- A Stack Rank Use Case exercise helps to identify and select those which provide high business impact and visibility to help gain business support, build confidence, and facilitate incremental learning. Use Case complexity and potential for success are also critical factors in the selection process.
Steps to Implement a Data Catalog
With the foundation in place, the implementation is ready to begin. There are 7 steps to implement a data catalog solution:

1. Choose Relevant Data Sources
The use cases may have multiple sources in scope, but not all may be needed. Focus on a limited, high-value set of sources required to achieve the use case objectives. These data sources could be comprised of databases, file systems, data warehouses, data lakes, data integration, BI reports, and others.
The richness of the source metadata, including technical descriptions, business descriptions, and custom tags, also play an important factor in demonstrating the features that a catalog provides.
2. Identify Key Stakeholders
A Data Catalog implementation requires that a team of key stakeholders be identified and involved from the beginning of the project. These stakeholders include members from both the Data Governance Office for management and oversight along with the Data Governance team involved in the day-to-day implementation activities.
Each stakeholder is responsible for their own area and includes roles such as project manager, coordinator, subject matter expert, business owner, data custodian/steward, and technical personnel. While these roles are clearly defined, communication between groups is a key success factor to ensure that all team members are in alignment.
3. Create Awareness
It’s important to create awareness of the catalog program within the organization. Engage and onboard internal stakeholders from the beginning with supporting information:
- An overview of the data catalog program
- The purpose of the data catalog
- The strategic and tactical benefits
Clearly define the expected involvement of line-of-business participants and encourage their involvement and contribution to benefit from the program. Each team member brings their own perspective from the business and technology sides and this interaction will create greater awareness of all aspects of the program and what it has to offer.
4. Define Technical Requirements
A well-defined set of business-driven requirements will determine what’s needed to configure the catalog. Items to be considered when defining the technical aspects include, but are not limited, to the following:
- What schemas within the database are relevant?
- What are the relevant categories of information to be auto-tagged/organized?
- How frequently should the catalog be refreshed?
- When should scans occur and what is the load window?
- What are the server and application details, including credentials?
- Are scanned assets available to everyone or limited to a specific group of users?
5. Configure and Ingest
Each data source in scope must be defined and configured within a data catalog as a resource that can access both the source metadata as well as a set of data within the application to provide accurate data profiling or auto-tagging results. Beyond the connection details and permissions required to extract data, the resource may be configured to define additional functionality (or processes) designed to enrich the data while ingesting it.
The metadata ingestion process is a straightforward one: Create a connection, define the scope of data to be ingested, resolve connection issues, and tune as needed.
Enrichment is configured in the application and is managed by the catalog once; when the configured job is started. Examples of enrichment processes include auto-tagging, data profiling, or creating custom attributes. The effort required to implement, test, and refine varies based upon the type of enrichment selected and expected results.
While the data is being processed, the catalog solution automates many of the data stewardship tasks using machine learning and artificial intelligence algorithms. Because every implementation is unique, the automated processes may not organize all data assets as expected, or perhaps additional descriptions about the asset needs to be added. These are examples where the data is manually curated and enriched by the user community.
6. Curate and Enrich the Data
Once data has been ingested, the task of stewardship is required to organize, manage, enrich, and provide high-quality, well-described assets data assets available throughout the organization. The goal of this data curation activity is to make this information current, easy to find, accessible, and relevant.
Data curation involves tasks such as maintaining and organizing data assets, adding annotations, assigning technical terms to business terms, and adding business or technical descriptions. As the manual curation is completed, the catalog will continue to apply those updates to all related assets within the catalog through automated processes.
7. Expand the Solution
Depending upon the goals of the organization, the initial implementation will continue to evolve within the catalog and through the expansion of the data governance platform.
Continue growing the catalog by loading the next set of resources in order to grow the library of data assets available to the business, along with adding additional product functionality such as ingesting data lineage for end-to-end impact analysis and understanding of data flows.
Beyond using the data catalog to discover, classify, and organize data assets, the data governance platform solution extends the value of the catalog by integrating with a data quality, data privacy, and data governance solution. These integrated, robust tools further enable self-service through a platform that:
- Provides business content of data, aligns technical and business assets, defines processes and policies, and enables the non-technical consumer with the ability to understand and access data
- Measures data quality against standard and custom metrics and scorecards
- Enables a user to define, identify, measure, report, and remediate data privacy exposure risk