

Challenge
There are many reasons that organizations choose to improve Data Quality. These reasons may include any or all of the following.
- Mergers and Acquisitions
- Increased Customer Satisfaction
- Increased Operational Efficiency
- Regulatory Compliance
- New Customer Acquisition
- Reduce IT or Business Costs
- Speed time to market
- Sell more to existing customers.
A data quality (DQ) project usually begins with a specific use case in mind. Regardless of the specific need, planning for the data quality project should be considered an iterative process. As change will always be prevalent, data quality must not be considered an absolute.
An organization must be cognizant of the continuing nature of data quality whenever undertaking a project that involves improving data quality. The goal of this Best Practice is to set forth principles that outline the iterative nature of data quality and the steps that should be considered when planning a data quality initiative. Experience has shown that applying these principles and steps will maximize the potential for ongoing success in data quality projects.
Description
Reasons for considering data quality as an iterative process stem from two core concepts. First, the level of sophistication around data quality will continue to improve as a DQ process is implemented. Specifically, as the results are disseminated throughout the organization, it will become easier to make decisions on the types of rules and standards that should be implemented; as everyone will be working from a single view of the truth. Although everyone may not agree on how data is being entered or identified, the baseline analysis will identify the standards (or lack thereof) currently in place. Once the initial data quality process is implemented, the iterative cycle begins. The users become more familiar with the data as they review the results of the data quality plans built to standardize, cleanse and de-duplicate the data. As each iterative cycle continues, the data stewards should determine if the business rules and reference dictionaries need to be modified to effectively address any new issues that arise.
The second reason that data quality continues to evolve is based on the premise that the data will not remain static. Although a baseline set of data quality rules will eventually be agreed upon, the assumption is that as soon as legacy data has been cleansed, standardized and de-duplicated it will ultimately change. This change could come from a user updating a record or a new data source being introduced that needs to become a part of the master data. In either case, the need to perform additional iterative cycles on the updated records and/or new sources should be considered. The frequency of these cycles will vary and are driven by the processes for data entry and transformation within an organization. This can result in processes that range from a need to cleanse data in real-time to performing a nightly or weekly batch processes with notifications. Profiles or applicable metrics should be monitored on a regular basis by Data Stewards to determine whether the business rules initially implemented continue to meet the data quality needs of the organization or have to be modified.
The questions that should be considered when evaluating the continuing and iterative nature of data quality include:
- Are the business rules and reference dictionaries meeting the needs of the organization when attempting to report on the underlying data?
- If a new data source is introduced, can the same data quality rules be applied or do new rules need to be developed to meet the type of data found in this new source?
- Have new data domains been introduced, containing sensitive data which must be monitored? For example, many organizations use the Data Quality toolset to monitor for potential regulatory compliance issues.
- Have new data sources been introduced which have data integrity issues?
- Are new data sources driving a need to enhance Metadata Manager Lineage artefacts or Business Glossary terms? From a trend perspective, is the quality of data improving over time? If not, what needs to be done to remedy the situation?
The answers to these questions will provide a framework to measure the current level of success achieved in implementing an iterative data quality initiative. These questions should be reflected upon frequently to determine if changes are needed to the data quality implementation or to the underlying business rules within a specific DQ process.
Although the reasons to iterate through the data may vary, the following steps will be present in each iterative cycle:
- Identify the problematic data elements that need to be addressed. Problematic data could include bad addresses, regulated data, duplicate records or incomplete data elements amongst others.
- Define the data quality rules and targets that need to be resolved. This includes rules for specific sources and content around the data quality areas that are being addressed.
- Design data quality plans to correct the problematic data. This could be one or many data quality plans, depending upon the scope and complexity of the source data.
- Implement quality improvement processes to identify problematic data on an ongoing basis. These processes should detect data anomalies which could lead to known and unknown data problems.
- Monitor and Repeat. This is done to ensure that the data quality plans correct the data to desired thresholds. Since data quality definitions can be adjusted based on business and data factors, this iterative review is essential to ensure that the stakeholders understand what will change with the data as it is cleansed and how that cleansed data may affect existing business processes and management reporting.
Example of the Iterative Process
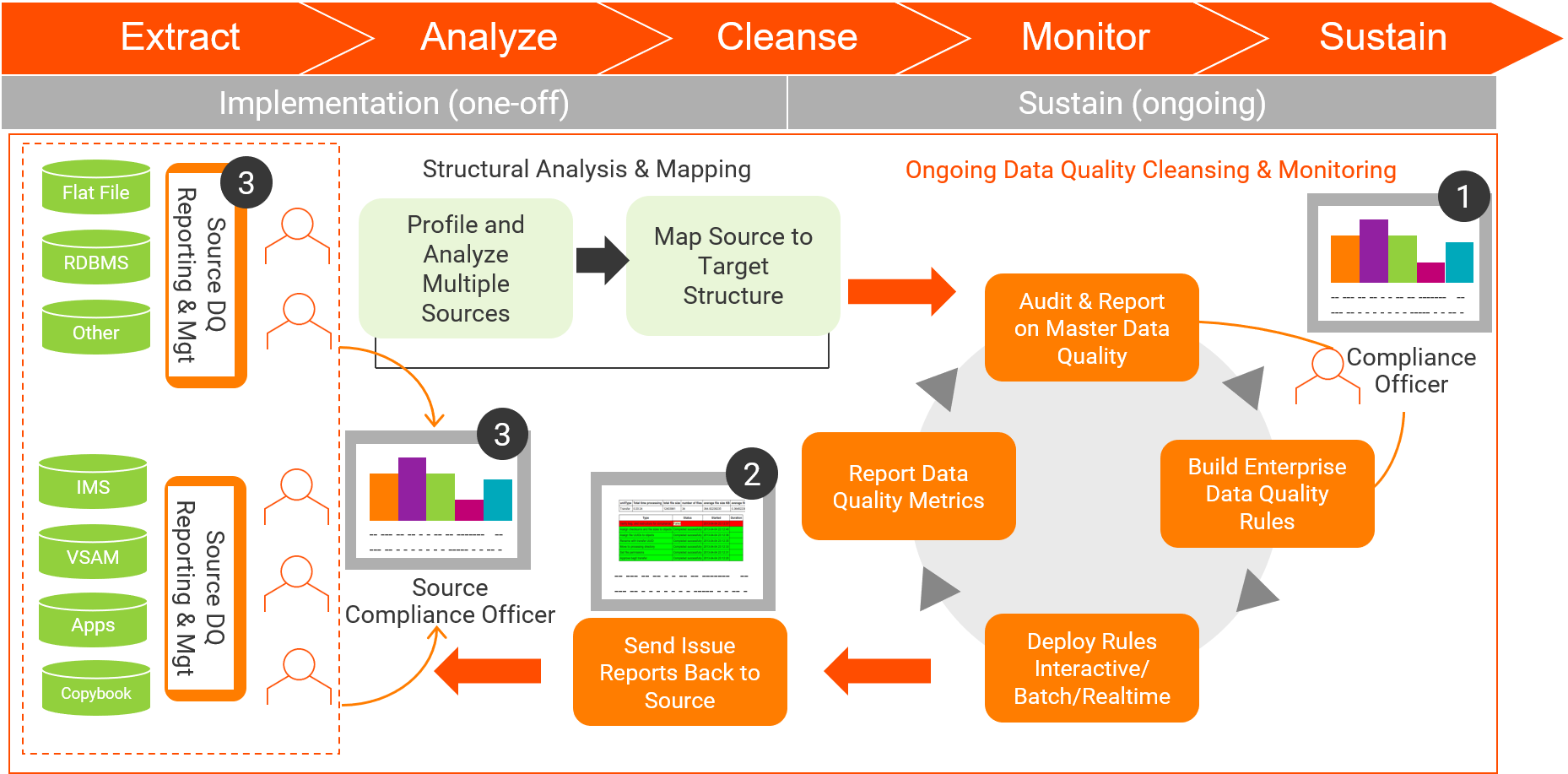
As noted in the above diagram, the iterative data quality process will continue to be leveraged within an organization as new master data is introduced. By having defined processes upfront, the ability to effectively leverage the data quality solution will be enhanced. An organization’s departments that are charged with implementing and monitoring data quality will be doing so within the confines of the enterprise wide rules and procedures of the organization.
The following points should be considered as an expansion to the five steps noted above:
- Identify & Measure Data Quality: This first point is key. The ability to understand the data within the confines of the six dimensions of data quality will form the foundation for the business rules and processes that will be put in place. Without performing an upfront assessment, the ability to effectively implement a data quality strategy will be negatively impacted. From an ongoing perspective, the data quality assessment will allow an organization to see how the historical data quality initiatives have caused the quality of the data to improve. Additionally, as new data enters the organization, the assessment will provide key information for making ongoing modifications to the data quality processes.
- Define Data Quality Rules & Targets: Once the assessment is complete, the second part of the analysis phase involves creating scorecards of the results. The scorecards will illustrate the success criteria and metrics for the data quality management initiative. From an ongoing perspective, this phase will involve performing trend analysis on the data and rules to ensure the data continues to conform to the rules defined during the data quality management initiative.
- Design Quality Improvement Processes: This phase involves the manipulation of the data to align it with the defined business rules. Examples of potential improvements include standardization, noise removal, aligning product attributes and implementing measures or classifications.
- Implement Quality Improvement Processes: Once the data has been standardized, an adjunct to the enhancement process involves the identification of duplicate data and taking action based upon the business rules that have been identified. The rules to identify and address duplicate data will continue to evolve. This evolution occurs as data stewards become more familiar with the data and as the policies and procedures outlined by the data governance committee become widely adopted throughout the organization. As this occurs, the ability to find additional duplicates or new relationships within the data arises.
- Monitor Data Quality versus Targets: The ability to monitor the data quality processes is critical. It provides the organization with a quick snapshot of the health of the data. Through analysis of the scorecard results, the data governance committee will have the information required to confidently drive additional modifications to the organization’s data quality strategy. Conversely, the scorecards and trend analysis results will provide the peace of mind that data quality is being effectively addressed within the organization.