
Challenge
Increasingly, a number of customers find that their Data Integration implementation must be available 24x7 without interruption or failure. This Best Practice describes the High Availability (HA) capabilities incorporated in PowerCenter and explains why it is critical to address both architectural (e.g., systems, hardware, firmware) and procedural (e.g., application design, code implementation, session/workflow features) recovery with HA.
Description
One of the common requirements of high volume data environments with non-stop operations is to minimize the risk exposure from system failures. PowerCenter’s High Availability Option provides failover, recovery and resilience for business critical, always-on data integration processes. When considering HA recovery, be sure to explore the following two components of HA that exist on all enterprise systems:
External Resilience
External resilience has to do with the integration and specification of domain name servers, database servers, FTP servers, network access servers in a defined, tested 24x7 configuration. The nature of Informatica’s data integration setup places it at many interface points in system integration. Before placing and configuring PowerCenter within an infrastructure that has an HA expectation, the following questions should be answered:
- Is the pre-existing set of servers already in a sustained HA configuration? Is there a schematic with applicable settings to use for reference? If so, is there a unit test or system test to exercise before installing PowerCenter products? It is important to remember, as a prerequisite for the PowerCenter architecture, the external systems must be HA.
- What are the bottlenecks or perceived failure points of the existing system? Are these bottlenecks likely to be exposed or heightened by placing PowerCenter in the infrastructure? (e.g., five times the amount of Oracle traffic, ten times the amount of DB2 traffic, a UNIX server that always shows 10% idle may now have twice as many processes running).
- Finally, if a proprietary solution (such as IBM HACMP or Veritas Storage Foundation for Windows) has been implemented successfully, this sets a different expectation. The client may merely want the grid capability of multiple PowerCenter nodes to recover Informatica tasks, and expect their O/S level HA capabilities to provide file system or server bootstrap recovery upon a fundamental failure of those back-end systems. If these back-end systems have a script/command capability to, for example, restart a repository service, PowerCenter can be installed in this fashion. However, PowerCenter's HA capability extends as far as the PowerCenter components.
Internal Resilience
In an HA PowerCenter environment key elements to keep in mind are:
- Rapid and constant connectivity to the repository metadata.
- Rapid and constant network connectivity between all gateway and worker nodes in the PowerCenter domain.
- A common highly-available storage system accessible to all PowerCenter domain nodes with one service name and one file protocol. Only domain nodes on the same operating system can share gateway and log files (see Admin Console->Domain->Properties->Log and Gateway Configuration).
Internal resilience occurs within the PowerCenter environment among PowerCenter services, the PowerCenter Client tools, and other client applications such as pmrep and pmcmd. Internal resilience can be configured at the following levels:
- Domain.Configure service connection resilience at the domain level in the general properties for the domain. The domain resilience timeout determines how long services attempt to connect as clients to application services or the Service Manager. The domain resilience properties are the default values for all services in the domain.
- Service.It is possible to configure service connection resilience in the advanced properties for an application service. When configuring connection resilience for an application service, this overrides the resilience values from the domain settings.
- Gateway.The master gateway node maintains a connection to the domain configuration database. If the domain configuration database becomes unavailable, the master gateway node tries to reconnect. The resilience timeout period depends on user activity and whether the domain has one or multiple gateway nodes:
- Single gateway node.If the domain has one gateway node, the gateway node tries to reconnect until a user or service tries to perform a domain operation. When a user tries to perform a domain operation, the master gateway node shuts down.
- Multiple gateway nodes.If the domain has multiple gateway nodes and the master gateway node cannot reconnect, then the master gateway node shuts down. If a user tries to perform a domain operation while the master gateway node is trying to connect, the master gateway node shuts down. If another gateway node is available, the domain elects a new master gateway node. The domain tries to connect to the domain configuration database with each gateway node. If none of the gateway nodes can connect, the domain shuts down and all domain operations fail.
Common Elements of Concern in an HA Configuration
Restart and Failover
Restart and Failover has to do with the Domain Services (Integration and Repository). If these services are not highly available, the scheduling, dependencies (e.g., touch files, ftp, etc.) and artifacts of the ETL process cannot be highly available.
If a service process becomes unavailable, the Service Manager can restart the process or fail it over to a backup node based on the availability of the node. When a service process restarts or fails over, the service restores the state of operation and begins recovery from the point of interruption.
Backup nodes can be configured for services with the high availability option. If an application service is configured to run on primary and backup nodes, one service process can run at a time. The following situations describe restart and failover for an application service:
- If the primary node running the service process becomes unavailable, the service fails over to a backup node. The primary node may be unavailable if it shuts down or if the connection to the node becomes unavailable.
- If the primary node running the service process is available, the domain tries to restart the process based on the restart options configured in the domain properties. If the process does not restart, the Service Manager can mark the process as failed. The service then fails over to a backup node and starts another process. If the Service Manager marks the process as failed, the administrator must enable the process after addressing any configuration problem.
If a service process fails over to a backup node, it does not fail back to the primary node when the node becomes available. The service process can be disabled on the backup node to cause it to fail back to the primary node.
Recovery
Recovery is the completion of operations after an interrupted service is restored. When a service recovers, it restores the state of operation and continues processing the job from the point of interruption. The state of operation for a service contains information about the service process. The PowerCenter services include the following states of operation:
- Service Manager. The Service Manager for each node in the domain maintains the state of service processes running on that node. If the master gateway shuts down, the newly elected master gateway collects the state information from each node to restore the state of the domain.
- Repository Service.The Repository Service maintains the state of operation in the repository. This includes information about repository locks, requests in progress and connected clients.
- Integration Service. The Integration Service maintains the state of operation in the shared storage configured for the service. This includes information about scheduled, running, and completed tasks for the service. The Integration Service maintains the session and workflow state of operations based on the recovery strategy configured for the session and workflow.
When designing a system that has HA recovery as a core component, be sure to include architectural and procedural recovery.
Architectural recovery for a PowerCenter domain involves the Service Manager, Repository Service and Integration Service restarting in a complete, sustainable and traceable manner. If the Service Manager and Repository Service recover, but the Integration Service cannot recover, the restart is not successful and has little value to a production environment. Field experience with PowerCenter has yielded these key items in planning a proper recovery upon a systemic failure:
- A PowerCenter domain cannot be established without at least one gateway node running. Even if a domain consists of ten worker nodes and one gateway node, none of the worker nodes can run ETL jobs without a gateway node managing the domain.
- An Integration Service cannot run without its associated Repository Service being started and connected to its metadata repository.
- A Repository Service cannot run without its metadata repository DBMS being started and accepting database connections. Often database connections are established on periodic windows that expire – which puts the repository offline.
- If the installed domain configuration is running from Authentication Module Configuration and the LDAP Principal User account becomes corrupt or inactive, all PowerCenter repository access is lost. If the installation uses any additional authentication outside PowerCenter (such as LDAP), an additional recovery and restart plan is required.
Procedural recovery is supported with many features of PowerCenter. Consider the following very simple mapping that might run in production for many ETL applications. Suppose there is a situation where the ftp server sending this ff_customer file is inconsistent. Many times the file is not there, but the processes depending on this must always run. The process is always insert only. You do not want the succession of ETL that follows this small process to fail - they can run to customer_stg with current records only. This setting in the Workflow Manager, Session, Properties would fit your need
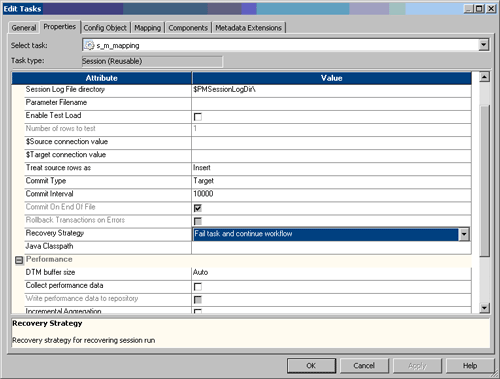
Since it is not critical the ff_customer records run each time, record the failure but continue the process. Now say the situation has changed. Sessions are failing on a PowerCenter server due to target database timeouts. A requirement is given that the session must recover from this:
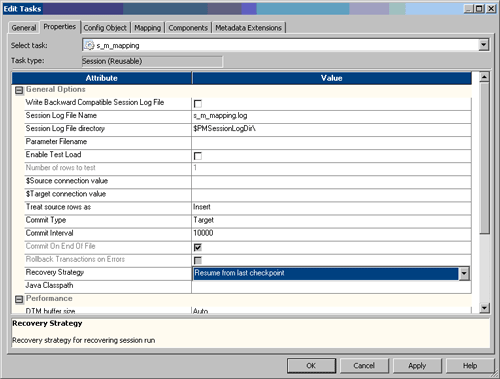
Resuming from last checkpoint restarts the process from its prior commit, allowing no loss of ETL work. To finish this second case, consider three basic items on the workflow side when the HA Option is implemented. An Integration Service in an HA environment can only recover those workflows marked with “Enable HA recovery”. For all critical workflows, this should be considered. For a mature set of ETL code running in QA or Production, the following workflow property may be considered:
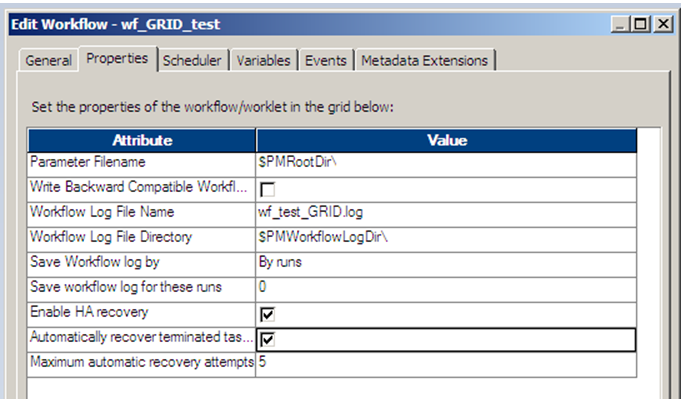
This would automatically recover tasks from where they failed in a workflow upon an application or system wide failure. Consider carefully the use of this feature, however. Remember, automated restart of critical ETL processes without interaction can have vast unintended side effects. For instance, if a database alias or synonym was dropped, all ETL targets may now refer to different objects than the original intent. Only PowerCenter environments with HA, mature production support practices, and a complete operations manual per Velocity, should expect complete recovery with this feature.
In an HA environment, certain components of the Domain can go offline while the Domain stays up to execute ETL jobs. This is a time to use the “Suspend On Error” feature from the General tab of Workflow settings. The backup Integration Server would then pick up this workflow and resume processing based on the resume settings of this workflow:
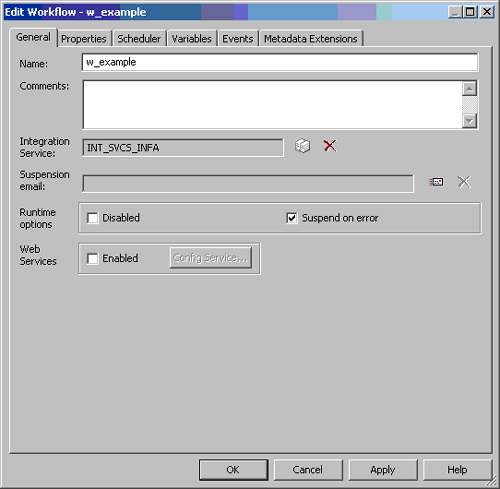
Features
A variety of HA features exist in PowerCenter. Specifically, they include:
- Integration Service HA option
- PowerCenter Enterprise Grid Option
- Repository Service HA option
First, proceed from an assumption that nodes have been provided such that a basic HA configuration of PowerCenter can take place. The HA solution should be completed with a shared file system supported by Informatica GCS. Your first step would always be implementing and thoroughly exercising a shared file system. Now, let’s address the options in order:
Integration Service HA Option
You must have the HA option on the license key for this to be available on install. Note that once the base PowerCenter install is configured, all nodes are available from the Admin Console->Domain->Integration Services->Grid/Node Assignments. With the HA (Primary/Backup) install complete, Integration Services are then displayed with both “P” and “B” in a configuration, with the current operating node highlighted:
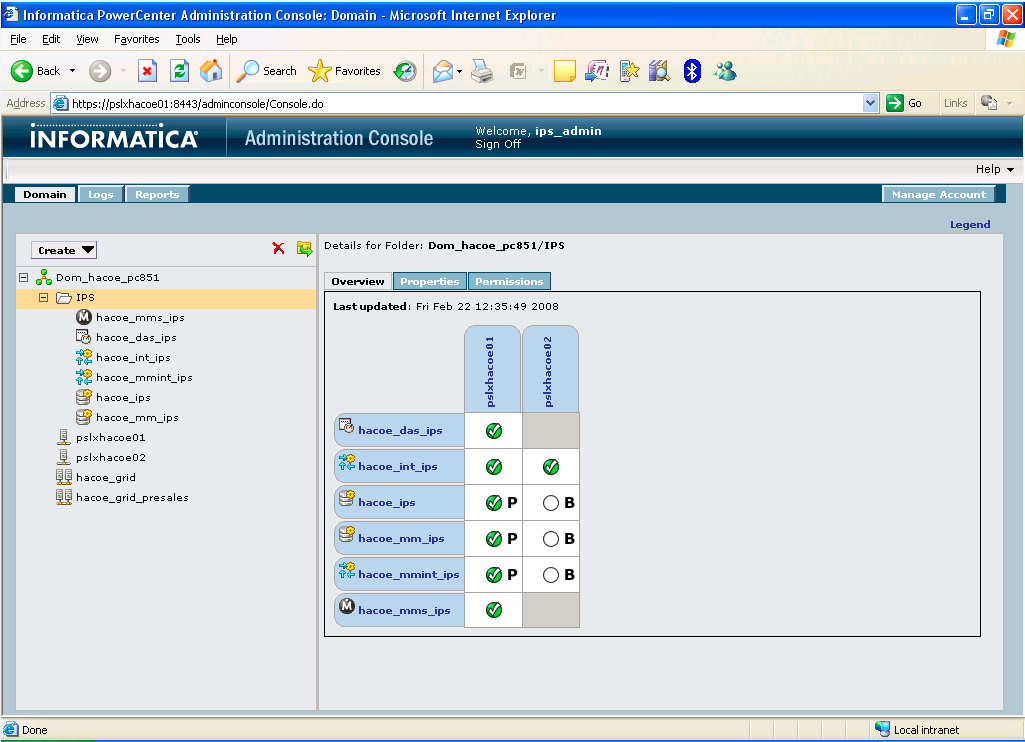
If a failure were to occur on this HA configuration, the Integration Service would poll the Domain for another Gateway Node, and then assign the Integration Service over to that Node. Then the “B” button would highlight showing this Node as running the Integration Service.
A vital component of configuring the Integration Service for HA is making sure the Integration Service files are stored in a shared persistent environment. The paths for Integration Service files must be specified for each Integration Service process. Examples of Integration Service files include run-time files, state of operation files, and session log files.
Each Integration Service process uses run-time files to process workflows and sessions. If an Integration Service is configured to run on a grid or to run on backup nodes, the run-time files must be stored in a shared location. Each node must have access to the run-time files used to process a session or workflow. This includes files such as parameter files, cache files, input files, and output files.
State of operation files must be accessible by all Integration Service processes. When an Integration Service is enabled, it creates files to store the state of operations for the service. The state of operations includes information such as the active service requests, scheduled tasks, and completed and running processes. If the service fails, the Integration Service can restore the state and recover operations from the point of interruption.
All Integration Service processes associated with an Integration Service must use the same shared location. However, each Integration Service can use a separate location. By default, the installation program creates a set of Integration Service directories in the server\infa_shared directory. The shared location for these directories can be set by configuring the process variable $PMRootDir to point to the same location for each Integration Service process. The key HA concern of this is $PMRootDir should be on the highly-available clustered file system mentioned above.
Integration Service Grid Option
The Grid Option provides implicit HA since the Integration Service can be configured as active/active to provide redundancy. The Server Grid option should be included on the license key for this to be available upon install. In configuring the $PMRootDir files for the Integration Service, use the method described above. Also, in Admin Console->Domain->Properties->Log and Gateway Configuration, the log and directory paths should be on the clustered file system mentioned above. A grid must be created before it can be used in a Power Center domain. Be sure to remember these key points:
- PowerCenter supports nodes from heterogeneous operating systems, bit modes, and others to be used within same domain. However, if there are heterogeneous nodes for a grid, then you can run Workflow on Grid. For the Session on Grid option, a homogeneous grid is required.
- A homogeneous grid is necessary for Session on Grid because a session may have a sharing cache file and other objects that may not be compatible with all of the operating systems.
If you have a large volume of disparate hardware, it is certainly possible to make perhaps two grids centered on two different operating systems. In either case, the performance of your clustered file system is going to affect the performance of your server grid, and should be considered as part of your performance/maintenance strategy.
Repository Service HA Option
You must have the HA option on the license key for this. In order to configure Repository Service for HA, use an incremental implementation of HA from a tested base configuration. After ensuring that the initial Repository Service settings (e.g., resilience timeout, codepage, connection timeout) and the DBMS repository containing the metadata are running and stable, make the second node Repository Backup. When it is running, go to Domain->Repository->Properties->Node Assignments->Edit and the browser window displays:

Click “OK” and the Repository Service is now configured in a Primary/Backup setup for the domain. To ensure the P/B setting, test the following elements of the configuration:
- Be certain the same version of the DBMS client is installed on the server and can access the metadata.
- Both nodes must be on the same clustered file system.
- Log onto the OS for the Backup Repository Service and ping the Domain Master Gateway Node. Be sure a reasonable response time is being given at an OS level (i.e., less than 5 seconds).
- Take the Primary Repository Service Node offline and validate that the polling, failover, restart process takes place in a methodical, traceable manner for the Repository Service on the Domain. This should be clearly visible from the node logs on the Primary and Secondary Repository Service boxes [$INFA_HOME/server/tomcat/logs] or from Admin Console->Repository->Logs.
Note: Remember that when a node is taken offline, you cannot access Admin Console from that node.
Using a Script to Monitor Informatica Services
A script should be used with the High Availability Option that will check all the Informatica Services in the domain as well as the domain itself. If any of the services are down the script can bring them back up. To implement the HA Option using a script, the Domain, Repository and Integration details need to be provided as input to the script; and the script needs to be scheduled to run at regular intervals. The script can be developed with eight functions (and one main function to check and bring up the services).
A script can be implemented in any environment by providing input in the <Input Environment Variables> section only. Comments have been provided for each function to make them easy to understand. Below is a brief description of the eight functions:
print_msg: |
Called to print output to the I/O and also writes to the log file. |
domain_service_lst: |
Accepts the list of services to be checked for in the domain. |
check_service: |
Calls the service manager, repository, and the integration functions internally to check if they are up and running. |
check_repo_service: |
Checks if the repository is up or down. If it is down it calls another function to bring it up. |
enable_repo_service: |
Called to enable the repository service. |
check_int_service: |
Checks if the integration is up or down. If it is down it calls another function to bring it up. |
enable_int_service: |
Called to enable the integration service. |
disable_int_service: |
Called to disable the integration service. |