

Challenge
Develop a Disaster Recovery (DR) Plan for PowerCenter running on Unix/Linux platforms. Design a PowerCenter data integration platform for high availability (HA) and disaster recovery that can support a variety of mission-critical and time-sensitive operational applications across multiple business and functional areas.
Description
To enable maximum resilience, the data integration platform design should provide redundancy and remoteness. The target architecture proposed in this document is based upon the following assumptions:
A PowerCenter HA option license is present.
A Cluster File System will be used to provide concurrent file access from multiple servers in order to provide a flexible, high-performance, and highly available platform for shared data in a SAN environment.
Four servers will be available for installing PowerCenter components.
- PowerCenter binaries, repository/domain database, and shared file system for PowerCenter working files are considered in a failover scenario.
The DR plan does not take into consideration source and target databases, ftp servers or scheduling tools.
A standby database server (which requires replicated logs for recovery) will be used as the disaster recovery solution for the database tier. It will provide disaster tolerance for both the PowerCenter repository and the domain database. As this server will be used to achieve high availability it should have performance characteristics in parity with the primary repository database server. Recovery time for storage can be reduced using near real-time replication of data-over-distance from the primary SAN to a mirror SAN. Storage vendors should be consulted for optimal SAN and mirror SAN configuration.
Primary Data Center During Normal Operation
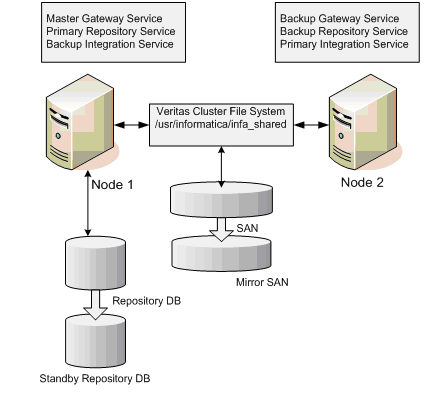
PowerCenter Domain During Normal Operation
Informatica Server Manager on Node 1 and Node 2 are running. Informatica Server Manager on Node 3 and Node 4 is shutdown.
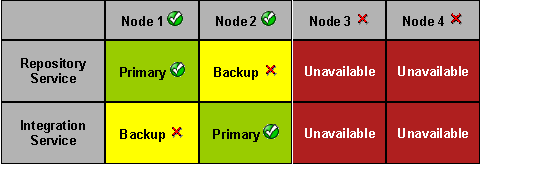
A node is a logical representation of a physical machine. Each node runs a Service Manager (SM) process to control the services running on that node. A node is considered unavailable if the SM process is not up and running. For example, the SM process may not be running if the administrator has shut down the machine or the SM process.
SM processes periodically exchange a heartbeat signal amongst themselves to detect any node/network failure. Upon detecting a primary (or backup) node failure, the remaining nodes determine the new primary (or backup) node via a distributed voting algorithm. Typically, the administrator will configure the OS to automatically start the SM whenever the OS boots up or in the event the SM fails unexpectedly. For unexpected failures of the SM, monitoring scripts should be used because the SM is the primary point of control for PowerCenter services on a node.
When PowerCenter is installed on a Unix/Linux platform, the same user id (uid) and group id (gid) should be created for all Unix/Linux users on Node1, Node2, Node3 and Node4. When the infa_shared directory is placed on a shared file system like CFS, all Unix/Linux users should be granted read/write access to the same files. For example, if a workflow running on Node1 creates a log file in the log directory, Node2, Node3 and Node4 should be able to read and update this file.
To install and configure PowerCenter services on four nodes:
- For the Node1 installation, choose the option to “create domain”.
- For the Node2, Node3 and Node4 installations choose the option to “join the domain”.
- Node1 will be the master gateway. For Node2, Node3 and Node4 choose “Serves as Gateway: Yes”.
- For Node 1, use the following URL to confirm that it is the Master Gateway:
http://node1_hostname:6001/coreservices/DomainService
The result should look like this:
/coreservices/AlertService : enabled /coreservices/AuthenticationService : initialized /coreservices/AuthorizationService : enabled /coreservices/DomainConfigurationService : enabled /coreservices/DomainService : [DOM_10004] Domain service is currently master gateway node and enabled. /coreservices/DomainService/InitTime : Fri Aug 03 09:59:03 EDT 2007 /coreservices/LicensingService : enabled /coreservices/LogService : enabled /coreservices/LogServiceAgent : initialized /coreservices/NodeConfigurationService : enabled - For Node2, Node 3 and Node 4 respectively, use the following URL to confirm that they are not Master Gateways:
http://node2_hostname:6001/coreservices/DomainService
The result should look like this:
/coreservices/AlertService : uninitialized /coreservices/AuthenticationService : initialized /coreservices/AuthorizationService : initialized /coreservices/DomainConfigurationService : initialized /coreservices/DomainService : [DOM_10005] Domain service is currently non-master gateway node and listening. /coreservices/DomainService/InitTime : Fri Aug 03 09:59:03 EDT 2007 /coreservices/LicensingService : initialized /coreservices/LogService : initialized /coreservices/LogServiceAgent : initialized /coreservices/NodeConfigurationService : enabled - Confirm the following settings:
- For Node1 Repository Service should be created as primary.
- For Node1 “Acts as backup Integration Service” should be checked.
- For Node2 Integration Service should be created as primary.
- For Node2 “Acts as backup Repository Service” should be checked.
- Node3 and Node4 should be assigned as backup nodes for Repository Service and Integration Service.
Note: During the failover in order for Node3 and Node4 to act as primary repository services, they will need to have access to the standby repository database.
After the installation, persistent cache files, parameter files, logs, and other run-time files should be configured to use the directory created on the shared file system by pointing the $PMRootDir variable to this directory. Otherwise a symbolic link can be created from the default infa_shared location to the infa_shared directory created on the shared file system.
After the initial set up, Node3 and Node4 should be shutdown from the Administration Console. During normal operations Node3 and Node4 will be unavailable. In the event of a failover to the secondary data center, it is assumed that the servers for Node1 and Node2 will become unavailable. By rebooting the hosts for Node3 and Node4 the following script-placed init.d will start the Service Manager process:
TOMCAT_HOME=/u01/app/informatica/pc8.0.0/server/tomcat/bin
case "$1" in
'start')
# Start the PowerCenter daemons:
su - pmuser -c "$TOMCAT_HOME/infaservice.sh startup"
exit
;;
'stop')
Esac
Every node in the domain sends a heartbeat to the primary gateway at a periodic interval. The default value for this interval is 15 seconds (this may change in a future release). The heartbeat is a message sent over an HTTP connection. As part of the heartbeat, each node also updates the gateway with the service processes currently running on the node. If a node fails to send a heartbeat during the default timeout value which is a multiple of the heartbeat interval (the default value is 90 seconds) then the primary gateway node marks the node unavailable and will failover any of the services running on that node. Six chances are given for the node to update the master before it is marked as down. This avoids any false alarms for a single packet loss or in cases of heavy network load where the packet delivery could take longer.
When Node3 and Node4 are started in the backup data center, they will try to establish a connection to the Master Gateway Node1. After failing to reach Node1, one of them will establish itself as the new Master Gateway. When normal operations resume, Node1 and Node2 will be rebooted and the Informatica Service Manager process will start on these nodes. Since the Informatica Service Manager process on Node3 and Node4 will be shutdown, Node1 will try to become the Master Gateway.
The change in configuration required for the DR servers (there will be two servers as in production) can be set up as a script to automate the switchover to DR. For example, the database connectivity should be configured such that failover to the standby database is transparent to the PowerCenter repository and the Domain database. All database connectivity information should be identical in both data centers to make sure that the same source and target databases are used. For scheduling tools, FTP servers and message queues additional steps are required to switch to the ETL platform in the backup data center.
As a result of using the PowerCenter HA option, redundancy in the primary data center is achieved. By using SAN mirroring, a standby repository database, and PowerCenter installations at the backup data center, remoteness is achieved. A further scale-out approach is recommended using the PowerCenter grid option to leverage resources on all of the servers. A single cluster file system across all nodes is essential to coordinate read/write access to the storage pool, ensure data integrity, and attain performance.
Backup Data Center After Failover From Primary Data Center
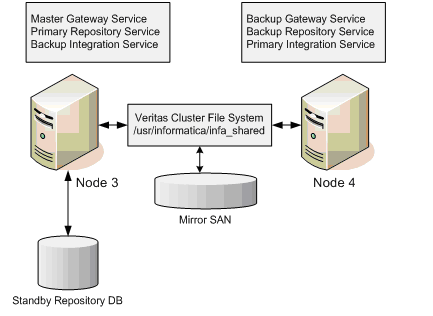
PowerCenter Domain During DR Operation
Informatica Server Manager on Node 2 and Node 3 are running. Informatica Server Manager on Node 1 and Node 2 is shutdown.
