
Challenge
Organizing variables and parameters in Parameter files and maintaining Parameter files for ease of use.
Description
Parameter files are a means of providing run time values for parameters and variables defined in a workflow, worklet, session, mapplet, or mapping. A parameter file can have values for multiple workflows, sessions, and mappings, and can be created using text editors such as notepad, vi, shell script, or an Informatica mapping.
Variable values are stored in the repository and can be changed within mappings. However, variable values specified in parameter files supersede values stored in the repository. The values stored in the repository can be cleared or reset using workflow manager.
Parameter File Contents
A Parameter File contains the values for variables and parameters. Although a parameter file can contain values for more than one workflow (or session), it is advisable to build a parameter file to contain values for a single or logical group of workflows for ease of administration. When using the command line mode to execute workflows, multiple parameter files can also be configured and used for a single workflow if the same workflow needs to be run with different parameters.
Types of Parameters and Variables
A parameter file contains the following types of parameters and variables:
- Service Variable. Defines a service variable for an Integration Service.
- Service Process Variable. Defines a service process variable for an Integration Service that runs on a specific node.
- Workflow Variable. References values and records information in a workflow. For example, use a workflow variable in a decision task to determine whether the previous task ran properly.
- Worklet Variable. References values and records information in a worklet. You can use predefined worklet variables in a parent workflow, but cannot use workflow variables from the parent workflow in a worklet.
- Session Parameter. Defines a value that can change from session to session, such a database connection or file name.
- Mapping Parameter. Defines a value that remains constant throughout a session, such as a state sales tax rate.
- Mapping Variable. Defines a value that can change during the session. The Integration Service saves the value of a mapping variable to the repository at the end of each successful session run and uses that value the next time the session runs.
Configuring Resources with Parameter File
If a session uses a parameter file, it must run on a node that has access to the file. You create a resource for the parameter file and make it available to one or more nodes. When you configure the session, you assign the parameter file resource as a required resource. The Load Balancer dispatches the Session task to a node that has the parameter file resource. If no node has the parameter file resource available, the session fails.
Configuring Pushdown Optimization with Parameter File
Depending on the database workload, you may want to use source-side, target-side, or full pushdown optimization at different times. For example, you may want to use partial pushdown optimization during the database's peak hours and full pushdown optimization when activity is low. Use the $$PushDownConfig mapping parameter to use different pushdown optimization configurations at different times. The parameter lets you run the same session using the different types of pushdown optimization.
When you configure the session, choose $$PushdownConfig for the Pushdown Optimization attribute.
Define the parameter in the parameter file. Enter one of the following values for $$PushdownConfig in the parameter file:
- None. The Integration Service processes all transformation logic for the session.
- Source. The Integration Service pushes part of the transformation logic to the source database.
- Source with View. The Integration Service creates a view to represent the SQL override value, and runs an SQL statement against this view to push part of the transformation logic to the source database.
- Target. The Integration Service pushes part of the transformation logic to the target database.
- Full. The Integration Service pushes all transformation logic to the database.
- Full with View. The Integration Service creates a view to represent the SQL override value, and runs an SQL statement against this view to push part of the transformation logic to the source database. The Integration Service pushes any remaining transformation logic to the target database.
Parameter File Name
Informatica recommends giving the Parameter File the same name as the workflow with a suffix of “.par”. This helps in identifying and linking the parameter file to a workflow.
Parameter File: Order of Precedence
While it is possible to assign Parameter Files to a session and a workflow, it is important to note that a file specified at the workflow level always supersedes files specified at session levels.
Parameter File Location
Each Integration Service process uses run-time files to process workflows and sessions. If you configure an Integration Service to run on a grid or to run on backup nodes, the run-time files must be stored in a shared location. Each node must have access to the run-time files used to process a session or workflow. This includes files such as parameter files, cache files, input files, and output files.
Place the Parameter Files in directory that can be accessed using the server variable. This helps to move the sessions and workflows to a different server without modifying workflow or session properties. You can override the location and name of parameter file specified in the session or workflow while executing workflows via the pmcmd command.
The following points apply to both Parameter and Variable files, however these are more relevant to Parameters and Parameter files, and are therefore detailed accordingly.
Multiple Parameter Files for a Workflow
To run a workflow with different sets of parameter values during every run:
- Create multiple parameter files with unique names.
- Change the parameter file name (to match the parameter file name defined in Session or Workflow properties). You can do this manually or by using a pre-session shell (or batch script).
- Run the workflow.
Alternatively, run the workflow using pmcmd with the -paramfile option in place of steps 2 and 3.
Generating Parameter Files
Based on requirements, you can obtain the values for certain parameters from relational tables or generate them programmatically. In such cases, the parameter files can be generated dynamically using shell (or batch scripts) or using Informatica mappings and sessions.
Consider a case where a session has to be executed only on specific dates (e.g., the last working day of every month), which are listed in a table. You can create the parameter file containing the next run date (extracted from the table) in more than one way.
Method 1:
- The workflow is configured to use a parameter file.
- The workflow has a decision task before running the session: comparing the Current System date against the date in the parameter file.
- Use a shell (or batch) script to create a parameter file. Use an SQL query to extract a single date, which is greater than the System Date (today) from the table and write it to a file with required format.
- The shell script uses pmcmd to run the workflow.
- The shell script is scheduled using cron or an external scheduler to run daily. The following figure shows the use of a shell script to generate a parameter file.
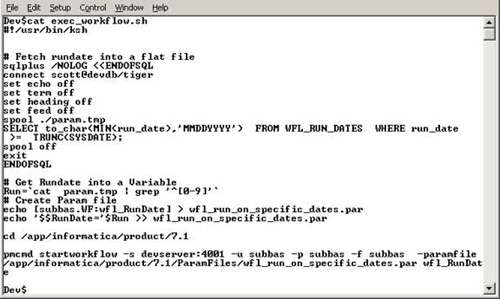
The following figure shows a generated parameter file.
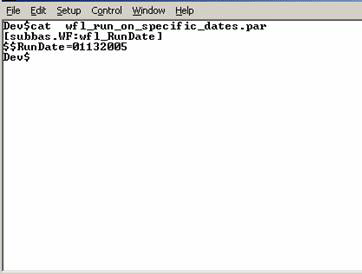
Method 2:
- The Workflow is configured to use a parameter file.
- The initial value for the data parameter is the first date on which the workflow is to run.
- The workflow has a decision task before running the session: comparing the Current System date against the date in the parameter file
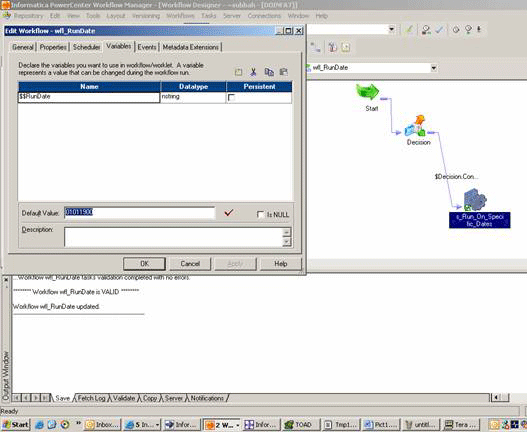
- The last task in the workflow generates the parameter file for the next run of the workflow (using a command task calling a shell script) or a session task, which uses a mapping. This task extracts a date that is greater than the system date (today) from the table and writes into parameter file in the required format.
- Schedule the workflow using Scheduler, to run daily (as shown in the following figure).
Parameter File Templates
In some other cases, the parameter values change between runs, but the change can be incorporated into the parameter files programmatically. There is no need to maintain separate parameter files for each run.
Consider, for example, a service provider who gets the source data for each client from flat files located in client-specific directories and writes processed data into global database. The source data structure, target data structure, and processing logic are all same. The log file for each client run has to be preserved in a client-specific directory. The directory names have the client id as part of directory structure (e.g., /app/data/Client_ID/)
You can complete the work for all clients using a set of mappings, sessions, and a workflow, with one parameter file per client. However, the number of parameter files may become cumbersome to manage when the number of clients increases.
In such cases, a parameter file template (i.e., a parameter file containing values for some parameters and placeholders for others) may prove useful. Use a shell (or batch) script at run time to create actual parameter file (for a specific client), replacing the placeholders with actual values, and then execute the workflow using pmcmd.
[PROJ_DP.WF:Client_Data]
$InputFile_1=/app/data/Client_ID/input/client_info.dat
$LogFile=/app/data/Client_ID/logfile/wfl_client_data_curdate.log
Using a script, replace “Client_ID” and “curdate” to actual values before executing the workflow.
The following text is an excerpt from a parameter file that contains service variables for one Integration Service and parameters for four workflows:
[Service:IntSvs_01]
$PMSuccessEmailUser=pcadmin@mail.com
$PMFailureEmailUser=pcadmin@mail.com
[HET_TGTS.WF:wf_TCOMMIT_INST_ALIAS]
$$platform=unix
[HET_TGTS.WF:wf_TGTS_ASC_ORDR.ST:s_TGTS_ASC_ORDR]
$$platform=unix
$DBConnection_ora=qasrvrk2_hp817
[ORDERS.WF:wf_PARAM_FILE.WT:WL_PARAM_Lvl_1]
$$DT_WL_lvl_1=02/01/2005 01:05:11
$$Double_WL_lvl_1=2.2
[ORDERS.WF:wf_PARAM_FILE.WT:WL_PARAM_Lvl_1.WT:NWL_PARAM_Lvl_2]
$$DT_WL_lvl_2=03/01/2005 01:01:01
$$Int_WL_lvl_2=3
$$String_WL_lvl_2=ccccc
Use Case 1: Fiscal Calendar-Based Processing
Some Financial and Retail industries use Fiscal calendar for accounting purposes. Use the mapping parameters to process the correct fiscal period.
For example, create a calendar table in the database with the mapping between the Gregorian calendar and fiscal calendar. Create mapping parameters in the mappings for the starting and ending dates. Create another mapping with the logic to create a parameter file. Run the parameter file creation session before running the main session.
The calendar table can be directly joined with the main table, but the performance may not be good in some databases depending upon how the indexes are defined. Using a parameter file can resolve the index and result in better performance.
Use Case 2: Incremental Data Extraction
Mapping parameters and variables can be used to extract inserted/updated data since previous extract. Use the mapping parameters or variables in the source qualifier to determine the beginning timestamp and the end timestamp for extraction.
For example, create a user-defined mapping variable $$PREVIOUS_RUN_DATE_TIME that saves the timestamp of the last row the Integration Service read in the previous session. Use this variable for the beginning timestamp and the built-in variable $$$SessStartTime for the end timestamp in the source filter.
Use the following filter to incrementally extract data from the database:
LOAN.record_update_timestamp > TO_DATE(‘$$PREVIOUS_DATE_TIME’) and
LOAN.record_update_timestamp <= TO_DATE(‘$$$SessStartTime’)
Use Case 3: Multi-Purpose Mapping
Mapping parameters can be used to extract data from different tables using a single mapping. In some cases the table name is the only difference between extracts.
For example, there are two similar extracts from tables FUTURE_ISSUER and EQUITY_ISSUER; the column names and data types within the tables are same. Use mapping parameter $$TABLE_NAME in the source qualifier SQL override, create two parameter files for each table name. Run the workflow using the pmcmd command with the corresponding parameter file, or create two sessions with corresponding parameter file.
Use Case 4: Using Workflow Variables
You can create variables within a workflow. When you create a variable in a workflow, it is valid only in that workflow. Use the variable in tasks within that workflow. You can edit and delete user-defined workflow variables.
Use user-defined variables when you need to make a workflow decision based on criteria you specify. For example, you create a workflow to load data to an orders database nightly. You also need to load a subset of this data to headquarters periodically, every tenth time you update the local orders database. Create separate sessions to update the local database and the one at headquarters. Use a user-defined variable to determine when to run the session that updates the orders database at headquarters.
To configure user-defined workflow variables, set up the workflow as follows:
Create a persistent workflow variable, $$WorkflowCount, to represent the number of times the workflow has run. Add a Start task and both sessions to the workflow. Place a Decision task after the session that updates the local orders database. Set up the decision condition to check to see if the number of workflow runs is evenly divisible by 10. Use the modulus (MOD) function to do this. Create an Assignment task to increment the $$WorkflowCount variable by one.
Link the Decision task to the session that updates the database at headquarters when the decision condition evaluates to true. Link it to the Assignment task when the decision condition evaluates to false.
When you configure workflow variables using conditions, the session that updates the local database runs every time the workflow runs. The session that updates the database at headquarters runs every 10th time the workflow runs.