
-
Manage your Success Plans and Engagements, gain key insights into your implementation journey, and collaborate with your CSMsSuccessAccelerate your Purchase to Value by engaging with Informatica for Customer SuccessAll your Engagements at one place
-
A collaborative platform to connect and grow with like-minded Informaticans across the globeCommunitiesConnect and collaborate with Informatica experts and championsHave a question? Start a Discussion and get immediate answers you are looking forCustomer-organized groups that meet online and in-person. Join today to network, share ideas, and get tips on how to get the most out of Informatica
-
Troubleshooting documents, product guides, how to videos, best practices, and moreKnowledge CenterOne-stop self-service portal for solutions, FAQs, Whitepapers, How Tos, Videos, and moreVideo channel for step-by-step instructions to use our products, best practices, troubleshooting tips, and much moreInformation library of the latest product documents
-
Rich resources to help you leverage full capabilities of our productsLearnRole-based training programs for the best ROIGet certified on Informatica products. Free, Foundation, or ProfessionalFree and unlimited modules based on your expertise level and journeySelf-guided, intuitive experience platform for outcome-focused product capabilities and use cases
-
Library of content to help you leverage the best of Informatica productsResourcesMost popular webinars on product architecture, best practices, and moreProduct Availability Matrix statements of Informatica productsMonthly support newsletterInformatica Support Guide and Statements, Quick Start Guides, and Cloud Product Description ScheduleEnd of Life statements of Informatica productsMonitor the status of your Informatica services across regions
- Velocity
- Strategy
-
Solutions
- Stages
-
More
-
Manage your Success Plans and Engagements, gain key insights into your implementation journey, and collaborate with your CSMsManage your Success Plans and Engagements, gain key insights into your implementation journey, and collaborate with your CSMsAccelerate your Purchase to Value by engaging with Informatica for Customer SuccessAll your Engagements at one place
-
A collaborative platform to connect and grow with like-minded Informaticans across the globeA collaborative platform to connect and grow with like-minded Informaticans across the globeConnect and collaborate with Informatica experts and championsHave a question? Start a Discussion and get immediate answers you are looking forCustomer-organized groups that meet online and in-person. Join today to network, share ideas, and get tips on how to get the most out of Informatica
-
Troubleshooting documents, product guides, how to videos, best practices, and moreTroubleshooting documents, product guides, how to videos, best practices, and moreOne-stop self-service portal for solutions, FAQs, Whitepapers, How Tos, Videos, and moreVideo channel for step-by-step instructions to use our products, best practices, troubleshooting tips, and much moreInformation library of the latest product documents
-
Rich resources to help you leverage full capabilities of our productsRich resources to help you leverage full capabilities of our productsRole-based training programs for the best ROIGet certified on Informatica products. Free, Foundation, or ProfessionalFree and unlimited modules based on your expertise level and journeySelf-guided, intuitive experience platform for outcome-focused product capabilities and use cases
-
Library of content to help you leverage the best of Informatica productsLibrary of content to help you leverage the best of Informatica productsMost popular webinars on product architecture, best practices, and moreProduct Availability Matrix statements of Informatica productsMonthly support newsletterInformatica Support Guide and Statements, Quick Start Guides, and Cloud Product Description ScheduleEnd of Life statements of Informatica productsMonitor the status of your Informatica services across regions
-
Automating Historical Data Load Process for Flat File Sources
Cloud Data Warehouse & Data Lake
Challenge
In a typical Data Warehousing environment the loading of full volume historical data load is often done during the project's Go Live phase. When historical data resides in relational databases, data can be incrementally extracted by adjusting date parameters. For flat file sources historical load process can be automated by following the procedure outlined below.
Description
Historical load process for flat files can be automated by using a simple shell script and an Informatica workflow with a command task. The Informatica workflow with command task is used to call the shell script by passing input arguments. The shell script iterates over a list of files present in $PMSourceFileDir (or any project specific Source file directory) and updates a file list. This file list is used by a child workflow to process actual business logic. After processing the file, the shell script archives files to a specified directory and simplifies the restart procedure if the job fails due to server outage or process-related issues.
This method of processing historical data files is considered a best practice as it doesn’t involve any manual intervention, thus eliminating any scope for manual errors. It also supports the fact that jobs should not be modified in a Production environment under any circumstances after project deployment. In addition, automatic processing of historical data files accelerates the data load process, and the application goes live faster when compared to manual processing of historical data. This method is superior to using file lists for the following reasons:
- The amount of data processed per batch can be regulated. For example, if there is a need to process 100-150 historical data files (each file containing millions of records) it would be a bad idea to use filelist if mappings contained caching transformations such as sorters or aggregators. These might cause performance issues during the load process. The methodology described in this article provides better control over the load process.
- Better Restartability – As files are processed in a sequential order one-by-one, it becomes very easy to restart the process from where it failed. Processed files are automatically moved to an archive folder.
- Traceability – It becomes easy to debug any data or process related issues as the exact process date and time of each data file is logged.
Process Flow

Script with Usage Example
The script below can be used in the project with slight modifications. This script fetches repository and integration service-related details from the infa_env environment file (Sample shown below).
Usage: $PMRootDir/Script/infa_load.sh [Source Folder] [File List] [Workflow] [FOLDER]
Mandatory flags:
- s: Source File directory
- l: file list name
- w: workflow
- p: Informatica Project Folder
- f: file pattern (like '*.txt')
Historical Data Load Script Sample
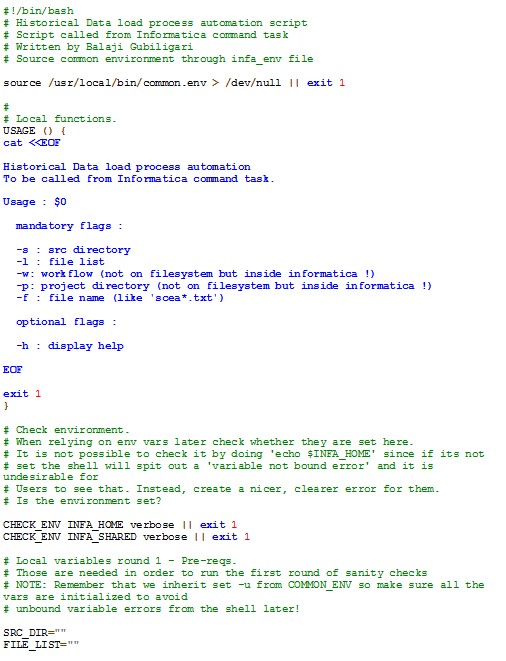


Informatica Environment File Sample
