
-
Manage your Success Plans and Engagements, gain key insights into your implementation journey, and collaborate with your CSMsSuccessAccelerate your Purchase to Value by engaging with Informatica for Customer SuccessAll your Engagements at one place
-
A collaborative platform to connect and grow with like-minded Informaticans across the globeCommunitiesConnect and collaborate with Informatica experts and championsHave a question? Start a Discussion and get immediate answers you are looking forCustomer-organized groups that meet online and in-person. Join today to network, share ideas, and get tips on how to get the most out of Informatica
-
Troubleshooting documents, product guides, how to videos, best practices, and moreKnowledge CenterOne-stop self-service portal for solutions, FAQs, Whitepapers, How Tos, Videos, and moreVideo channel for step-by-step instructions to use our products, best practices, troubleshooting tips, and much moreInformation library of the latest product documents
-
Rich resources to help you leverage full capabilities of our productsLearnRole-based training programs for the best ROIGet certified on Informatica products. Free, Foundation, or ProfessionalFree and unlimited modules based on your expertise level and journeySelf-guided, intuitive experience platform for outcome-focused product capabilities and use cases
-
Library of content to help you leverage the best of Informatica productsResourcesMost popular webinars on product architecture, best practices, and moreProduct Availability Matrix statements of Informatica productsMonthly support newsletterInformatica Support Guide and Statements, Quick Start Guides, and Cloud Product Description ScheduleEnd of Life statements of Informatica productsMonitor the status of your Informatica services across regions
- Velocity
- Strategy
-
Solutions
- Stages
-
More
-
Manage your Success Plans and Engagements, gain key insights into your implementation journey, and collaborate with your CSMsManage your Success Plans and Engagements, gain key insights into your implementation journey, and collaborate with your CSMsAccelerate your Purchase to Value by engaging with Informatica for Customer SuccessAll your Engagements at one place
-
A collaborative platform to connect and grow with like-minded Informaticans across the globeA collaborative platform to connect and grow with like-minded Informaticans across the globeConnect and collaborate with Informatica experts and championsHave a question? Start a Discussion and get immediate answers you are looking forCustomer-organized groups that meet online and in-person. Join today to network, share ideas, and get tips on how to get the most out of Informatica
-
Troubleshooting documents, product guides, how to videos, best practices, and moreTroubleshooting documents, product guides, how to videos, best practices, and moreOne-stop self-service portal for solutions, FAQs, Whitepapers, How Tos, Videos, and moreVideo channel for step-by-step instructions to use our products, best practices, troubleshooting tips, and much moreInformation library of the latest product documents
-
Rich resources to help you leverage full capabilities of our productsRich resources to help you leverage full capabilities of our productsRole-based training programs for the best ROIGet certified on Informatica products. Free, Foundation, or ProfessionalFree and unlimited modules based on your expertise level and journeySelf-guided, intuitive experience platform for outcome-focused product capabilities and use cases
-
Library of content to help you leverage the best of Informatica productsLibrary of content to help you leverage the best of Informatica productsMost popular webinars on product architecture, best practices, and moreProduct Availability Matrix statements of Informatica productsMonthly support newsletterInformatica Support Guide and Statements, Quick Start Guides, and Cloud Product Description ScheduleEnd of Life statements of Informatica productsMonitor the status of your Informatica services across regions
-
Product Data Modeling
Challenge
Product data residing in multiple siloed and disparate systems means there is no way to know which data is accurate or which has poor data quality . Manual effort is needed to reconcile data, which could potentially lead to wrong decisions. Having the ability and flexibility to define and adjust the data model is key for any master data solution. An emphasis must be made to determine an easy-to-use business user experience while also defining or extending the data model.
Description
Product 360 is responsible for central control of all data sources and data consumers, and for the internal organization of product data. Flexible data modeling allows implementation of a consistent data model and, on this basis, the integration of heterogeneous data landscapes.
The key starting point to any implementation is to define and agree on the data model. Product 360 has predefined data models that can be used for customer solutions. These models are defined and explicitly configured within the system. The data model is not built based on discovery, but by selecting the model that best fits the requirements.
Data Model Paradigm
The Product 360 data model paradigm supports three types of tiers – a single tier, two tiers, and three tiers. To better understand the data model, it is important to recognize what constitutes a product and an item.



A product represents a group of items containing common attributes and data. Items belonging to the same product share a set of so-called “defining attributes.” The values provided for these attributes make the item unique within the product (SKU resolution). The product itself is not represented by a physical thing. It cannot be purchased or produced, nor put on stock or sold. It is only an information container for the valid common information for all assigned items.
An item is a uniquely defined thing or service which can be produced and/or bought, able to put on stock, and to be sold again. The master data of an item contains all unique information needed to identify and manage it. Depending on product type, there are different criteria which should be considered as "defining" attributes.
Defining Attribute: An attribute which will trigger a new stock keeping unit (SKU). The combination of defining attributes must be unique for that item. For example, in P360, there can only be 1 64GB iPhone11 in space gray. A 256GB space gray iPhone is a separate SKU and hence a different item in P360.
Descriptive Attribute: An attribute used to describe the product. This attribute will be the same across the same set of items. For example, each golf shirt will have the same material, style, and other specifications irrespective of the color and size.
Single Tier Data Model
This model is a one level flat structure where each entity is stored as an item. All the information is stored at the item level and will be maintained and enriched there.
Let us use the Harry Potter series as an example. There are seven books in the series: Harry Potter and the Sorcerer's Stone, Harry Potter and the Chamber of Secrets, and Harry Potter and the Prisoner of Azkaban, and so on. Each book has a different publication date, a different description, and completely different images. Since each book is very distinct from the other (even within the same series), this would be a good candidate for the single tier data model. Each book would be maintained as a separate item in P360.
Two Tier Data Model
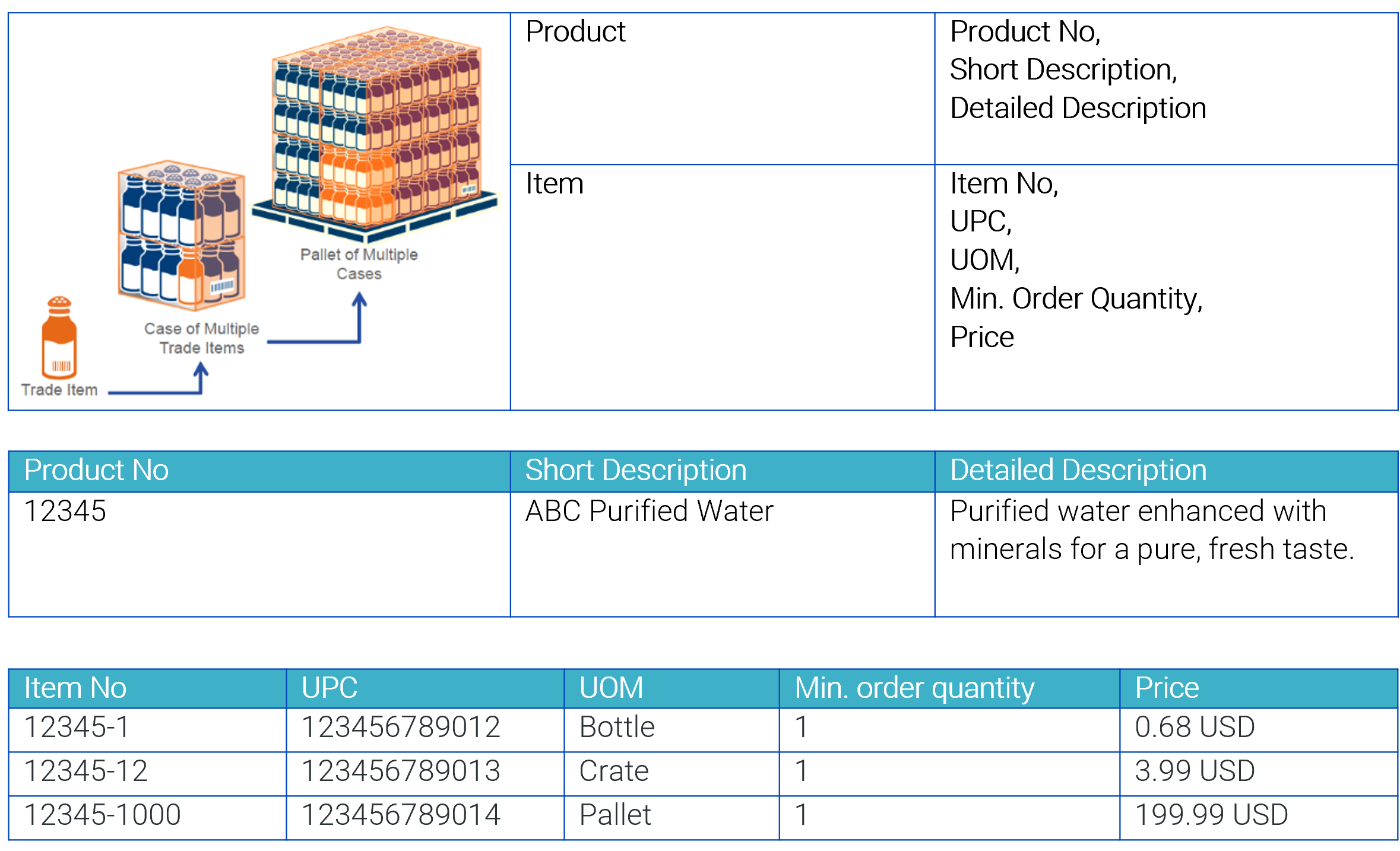
An item belongs to exactly one product. As defined above, an item represents a concrete variation of a product that typically contains differing defining attributes or packaging information from other items. Usually, which data is provided on product level to which is on the item level runs the gamut from “nearly all is common, only units and prices are different” to “nearly all varies, and only fewer common descriptions are shared.”
The most typical scenario occurs where items representing the variation of a product differ in their values of the so-called defining attributes. On the product level, all common names, descriptions, manufacturer information, images, and data sheets including descriptive attributes are provided. The product declares the defining attributes. The items of the product will provide values for these attributes. These attributes vary over the items assigned and make them unique. The items must provide values for the defining attributes. Optionally, additional item-specific descriptions can be specified on item level example order information, logistic data, and price information. Typically, these descriptions are defined at the item level.
For example, mineral water filled into bottles. The mineral water can be made ordered as single bottle, a case of twelve bottles, or packaged on a pallet with 160 crates. The item number and other identifying values are unique to differentiate ordering a single bottle, a case, or a palette of the mineral water. The price will vary per item and is based on the unit sold.
In this model, data elements like Short and Detailed descriptions are stored at the product level, and defining elements like UPC, unit of measure (UOM), minimum order quantity, and price are stored at the item level.
When to Use Two Tier
- When what constitutes a product (product family) can be clearly defined. For example: Brand, Model No, Series
- Generally, when 80% or more items have parent products.
- You can identify attributes that move up the hierarchy to make the process more efficient. For example: Brand or description
Another case for using Common projects for resources that may be used only once, is for external resources. If external resources are provided (i.e., wsdls and schema pointing to external services) they should be separated from the application Project. In this way, when the external system makes changes they can be addressed in a project specifically for that system.
For example, if projects use a selection of WSDL and XML schema resources to interact with web services offered by Yahoo Shopping, and those resources have been obtained from Yahoo, then it is appropriate to dedicate a common resource project to hold those files, called “YahooShoppingResources” or something similar.
Three Tier Data Model
A vast majority of solutions can be supported with a two-tier model which could include retail, distribution, and manufacturers. Clients that have an additional level of complexity can utilize the three tiers. This model can be useful for complex fashion retailers or retailers that have a distribution chain that can include wholesaler/brokers.
In this model, an additional tier for maintenance of product data is available as an option. This hierarchical arrangement allows information that is identical for all objects at subsequent levels to be maintained only once. This dramatically reduces maintenance work and improves consistency and data quality.
Typically, apparel companies have their processes aligned with respect to the three-tier model. Oftentimes, this is due to their legacy systems which are also set up as a three-tier model and aligns their processes accordingly.
The background of this requirement is to maintain data which is relevant for all items below on a higher level, which leads to the fact that the data must be maintained only once. With this approach, a faster data maintenance can be achieved. This also ensures that all items below this variant are consistent, and that it is possible to set specific rights for variant fields. Also, the data does not need to be stored redundantly, which could result in a higher performance.
Typical examples of individual levels include different cuts for the product level, containing detailed text information and attributes, different color options at the variant level, associated media assets, the sizes of the clothing with the unique order number, and price information typically on item level. The variants entity contains the full range of functions of the familiar entities. For example, for the assignment of media assets, references, features, attributes, and own rights.

When to Use Three-Tier
When evaluating the applicability of the three-tier model, it is particularly important to have a look at where the data comes from and where the data goes.
- Is the source of the data available in three-tiers as well?
- Are the target systems (e.g., eCommerce system) able to handle three-tier data as well?
If this is not the case, then it can be complicated to split or aggregate the data and the effort should be evaluated holistically.
Additional questions that can also be asked include:
- Do you need to create relationships between variants and other objects?
- Do you need to store media assets on the variant tier?
If you do not need to explicitly store information on the variant level, it is not recommended to use the three-tier paradigm because it can introduce additional complexity.
Benefits of Using Tiers
- Faster Data maintenance and faster time to market (e.g., descriptions) only need to be maintained at the product and not on multiple items.
- Better data quality and consistency (e.g., it is ensured that all items belonging to the same variant have the same media asset)
- Better rights/roles management possibility to set specific permissions on variant editing.
- Much easier to perform data governance when lot of general information is at singular level.
What to Keep in Mind?
- No mixed mode is supported, only two-tier or three-tier.
- An item is only allowed to have one higher-level variant.
- A variant can have only one higher-level product.
- Using the 3-tier model increases complexity in several areas for the user and may worsen the usability.
- In the Desktop UI there are no generic views, so there is one additional view everywhere product/item views are available today.
- As data access gets more complicated, customization may be needed for data aggregation and splitting, (e.g., accessing higher-level sub-entities in export.)
- It is highly recommended to use the two-tier paradigm (Product – Items) or one-tier (Items) wherever possible.