
-
Manage your Success Plans and Engagements, gain key insights into your implementation journey, and collaborate with your CSMsSuccessAccelerate your Purchase to Value by engaging with Informatica for Customer SuccessAll your Engagements at one place
-
A collaborative platform to connect and grow with like-minded Informaticans across the globeCommunitiesConnect and collaborate with Informatica experts and championsHave a question? Start a Discussion and get immediate answers you are looking forCustomer-organized groups that meet online and in-person. Join today to network, share ideas, and get tips on how to get the most out of Informatica
-
Troubleshooting documents, product guides, how to videos, best practices, and moreKnowledge CenterOne-stop self-service portal for solutions, FAQs, Whitepapers, How Tos, Videos, and moreVideo channel for step-by-step instructions to use our products, best practices, troubleshooting tips, and much moreInformation library of the latest product documents
-
Rich resources to help you leverage full capabilities of our productsLearnRole-based training programs for the best ROIGet certified on Informatica products. Free, Foundation, or ProfessionalFree and unlimited modules based on your expertise level and journeySelf-guided, intuitive experience platform for outcome-focused product capabilities and use cases
-
Library of content to help you leverage the best of Informatica productsResourcesMost popular webinars on product architecture, best practices, and moreProduct Availability Matrix statements of Informatica productsMonthly support newsletterInformatica Support Guide and Statements, Quick Start Guides, and Cloud Product Description ScheduleEnd of Life statements of Informatica productsMonitor the status of your Informatica services across regions
- Velocity
- Strategy
-
Solutions
- Stages
-
More
-
Manage your Success Plans and Engagements, gain key insights into your implementation journey, and collaborate with your CSMsManage your Success Plans and Engagements, gain key insights into your implementation journey, and collaborate with your CSMsAccelerate your Purchase to Value by engaging with Informatica for Customer SuccessAll your Engagements at one place
-
A collaborative platform to connect and grow with like-minded Informaticans across the globeA collaborative platform to connect and grow with like-minded Informaticans across the globeConnect and collaborate with Informatica experts and championsHave a question? Start a Discussion and get immediate answers you are looking forCustomer-organized groups that meet online and in-person. Join today to network, share ideas, and get tips on how to get the most out of Informatica
-
Troubleshooting documents, product guides, how to videos, best practices, and moreTroubleshooting documents, product guides, how to videos, best practices, and moreOne-stop self-service portal for solutions, FAQs, Whitepapers, How Tos, Videos, and moreVideo channel for step-by-step instructions to use our products, best practices, troubleshooting tips, and much moreInformation library of the latest product documents
-
Rich resources to help you leverage full capabilities of our productsRich resources to help you leverage full capabilities of our productsRole-based training programs for the best ROIGet certified on Informatica products. Free, Foundation, or ProfessionalFree and unlimited modules based on your expertise level and journeySelf-guided, intuitive experience platform for outcome-focused product capabilities and use cases
-
Library of content to help you leverage the best of Informatica productsLibrary of content to help you leverage the best of Informatica productsMost popular webinars on product architecture, best practices, and moreProduct Availability Matrix statements of Informatica productsMonthly support newsletterInformatica Support Guide and Statements, Quick Start Guides, and Cloud Product Description ScheduleEnd of Life statements of Informatica productsMonitor the status of your Informatica services across regions
-
Estimating the Database Size
Cloud Data Warehouse & Data Lake
Challenge
The optimal planned configuration of database servers to support the operational workloads requires sizing. Database sizing involves estimating the types and sizes of the components of a data architecture to produce a sizing document. An effective sizing activity involves a number of different roles including data architects, database administrators, and business analysts. Database administrators may also require size estimates for database capacity planning.
Description
The first step in database sizing is to review the system requirements to define:
- Expected Macro Data Architecture - Will there be staging areas, operational data stores, centralized data warehouse and/or master data databases and data marts?
- Expected Data Architecture Elements - Each additional database element (table, index and column) requires more space. This is especially true when data is replicated across multiple systems such as, a data warehouse where the infrastructure includes an operational data store as well. The same data in the ODS will be present in the warehouse as well, albeit in a different format.
- Expected Source Data Volume - It is useful to analyze how each row in the source system translates into the target system. In most situations the row count in the target system can be calculated by following the data flows from the source to the target. For example, say a sales order table is being built by denormalizing a source table. The source table holds sales data for 12 months in a single row (one column for each month). Each row in the source translates to 12 rows in the target. So a source table with one million rows ends up as a 12 million row table.
- Data Granularity and Retention Period - Granularity refers to the lowest level of information that is going to be stored in a fact table. Granularity affects the size of a database to a great extent, especially for aggregate tables. The level at which a table has been aggregated increases or decreases a table's row count. For example, a sales order fact table's size is likely to be greatly affected by whether the table is being aggregated at a monthly level or at a quarterly level. The granularity of fact tables is determined by the dimensions linked to that table. The number of dimensions that are connected to the fact tables affects the granularity of the table and in turn the disk space occupied.
- Retention Period - In some cases the retention period that will apply to the data needs to be considered. This may vary. For example, data in a staging area for a data warehouse may require lesser retention period than the data that is going to reside in the access layer. Sizing needs to include estimates if a dual data load takes place in real-time to a backup server to support high availability or disaster recovery or maintaining a like production environment.
- Load Frequency and Method - Load frequency affects the space requirements for the staging areas. A load plan that updates a target less frequently will often load more data in one go. Therefore, more space is required by the staging areas. A full refresh requires more space for the same reason.
Determining Growth Projections
One way to estimate projections of data growth over time is to use scenario analysis. As an example, for scenario analysis of a sales tracking data mart a number of sales transactions to be stored can be used as the basis for the sizing estimate. In the first year, 10 million sales transactions are expected; this equates to 10 million fact-table records.
Next, use the sales growth forecasts for the upcoming years for database growth calculations. That is, an annual sales growth rate of 10 percent translates into 11 million fact table records for the next year. At the end of five years, the fact table is likely to contain about 60 million records. Calculate other estimates based on five-percent annual sales growth (case 1) and 20-percent annual sales growth (case 2). Multiple projections for best and worst case scenarios can be very helpful.
Consider that growth may not be a linear percentage. Looking at Fibonacci or exponential growth number sets for a period of time may help plan and cost some aspects of data growth.
Oracle Table Space Prediction Model
Oracle (10g and onwards) provides a mechanism to predict the growth of a database. This feature is useful for predicting table space requirements.
Oracle incorporates a table space prediction model in the database engine that provides projected statistics for space used by a table. The following Oracle 10g query returns projected space usage statistics for tables with data:
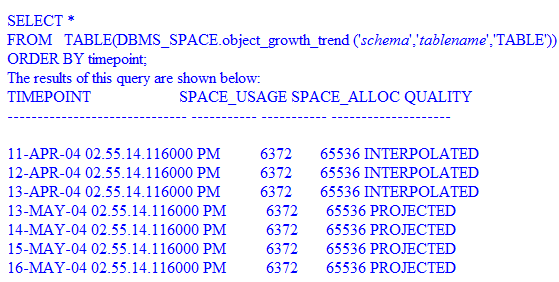
The QUALITY column indicates the quality of the output as follows:
- GOOD - The data for the time point relates to data within the Automatic Workload Repository (AWR), an inbuilt repository that exists in every Oracle database. Oracle takes snapshots of vital statistics in this repository at regular intervals with a timestamp within 10 percent of the interval.
- INTERPOLATED - The data for this time point did not meet the GOOD criteria but was based on data gathered before and after the time point.
- PROJECTED - The time point is in the future, so the data is estimated based on previous growth statistics.
Baseline Volumetric
Next, use the physical data models for the sources and the target architecture to develop a baseline sizing estimate. The administration guides for most databases contain sizing guidelines for the various database structures such as tables, indexes, sort space, data files, log files, and database cache.
Develop a detailed sizing using a worksheet inventory of the tables and indexes from the physical data model, along with field data types and field sizes. Various database products use different storage methods for data types. For this reason, be sure to use the database manuals to determine the size of each data type. Add up the field sizes to determine row size. Then use the data volume projections to determine the number of rows to multiply by the table size.
The default estimate for index size is to assume same size as the table size. Also estimate the temporary space for sort operations. For data warehouse applications where summarizations are common, plan on large temporary spaces. The temporary space can be as much as 1.5 times larger than the largest table in the database.
Another approach that is useful is to load the data architecture with representative data and determine the resulting database sizes. This test load can be a fraction of the actual data and is used only to gather basic sizing statistics. Then need to apply growth projections to these statistics. For example, after loading ten thousand sample records to the fact table, size is determined to be 10MB. Based on the scenario analysis, expect this fact table to contain 60 million records after five years. So, the estimated size for the fact table is about 60GB [i.e., 10 MB * (60,000,000/10,000)]. Do not forget to add indexes and summary tables to the calculations.
Estimating
When there is not enough information to calculate an estimate as described above, use educated guesses and rules of thumb to develop as reasonable an estimate as possible.
- If the source data model is not available, use what is known to determine the source data for an estimate of average field size and average number of fields in a row to determine table size. Based on the understanding of transaction volume over time, determine the growth metrics for each type of data and calculate the source data volume (SDV) from table size and growth metrics.
- If the target data architecture is not complete sufficiently to determine table sizes, base estimates on multiples of the SDV:
- If it includes staging areas: add another SDV for any source subject area that will be staged, multiplied by the number of loads that will be retained in staging.
- If data will be consolidated into an operational data store, add the SDV multiplied by the number of loads to be retained in the ODS for historical purposes (e.g., keeping one year’s worth of monthly loads = 12 x SDV)
- Data warehouse architectures are based on the frequency and granularity of the data in the warehouse; this may be another SDV + (.3n x SDV where n = number of time periods loaded in the warehouse over time)
- If the data architecture includes aggregates, add a percentage of the warehouse volume based on how much of the warehouse data will be aggregated and to what level (for example, if the rollup level represents 10 percent of the dimensions at the details level, use 10 percent).
- Similarly, for data marts add a percentage of the data warehouse based on how much of the warehouse data is moved to the data mart.
- Be sure to consider the growth projections over time and the history to be retained in all the calculations.
It is very often the case that there is much more data than expected. Therefore Informatica recommends adding a reasonable margin of safety to the calculations. From a risk perspective it is better to over purchase some storage, especially if it is of the inexpensive kind, than to find the project is held up later and additional hardware related costs are incurred as storage has to again be acquired.
‘Database Sizing Model’ calculator is contained in ‘Database Capacity Planning’ accelerator.