

Challenge
The analysis of data is a critical step in any master data project. This is the process of inspecting, cleaning, transforming and modelling data to support the design of a Cloud Customer 360 solution.
Description
The purpose of this exercise is to gain a comprehensive understanding of the data available to the organization and to determine the data set that is in scope for the Cloud Customer 360 project. This will help business users identify master data attributes, derive data quality trends, determine transformation/translation rules for cleansing and standardization and understand how these decisions will impact the matching rules.
Step 1. Data Quality Analysis
There are many processes and approaches that may be used to analyze data, some will be industry or data set specific. This is an outline of the basic checklist items that must be considered when undertaking a Cloud Customer 360 project. It is important to have a holistic view of the data and system landscape.
- Identify at the field level the data that is coming from each source.
- What system is the data coming from?
- What data fields are coming from each system?
- This data can then be catalogued and profiled as dictated by the business requirements. For example:
- Catalog/Content: number of nulls, uniqueness, frequency of values, ranges, patterns and min/max values.
- Cross Table/Source Analysis: relationships, mapping similar columns from multiple sources, analyzing shared content among master data attributes across sources, foreign keys and inferred foreign keys, derived enterprise-level data quality and standardization rules.
- Determine characteristics per source – it is important to understand the purpose and intent behind a data extract and to determine what data transformations and what data exclusions are being done in the data extract programs. If direct connectivity to the source system database is available then joins and lookups may need to be developed as part of the delivery.
- Determine data quality issues – an obvious step, this can be given more meaning by developing a suitable framework for an organization’s data/requirements. The usual measures are completeness, standardization (consistency), validity (the data could be complete but not valid for use), age, last used and related business information (e.g., Opportunity age).
- Check the primary keys that are available in the data.
- Understand the data cardinality - In the relational model, tables can be related as "one to many" or "many-to-many." This is the cardinality of a given table in relation to another.
- Determine total data volumes, initial load volume, expected data volumes and load frequencies.
- Define extract filter rules or special initial data load (IDL) requirements for each system. This activity may be iterative and should be controlled accordingly.
- Identify invalid data conditions that can or cannot be remedied through data cleansing. Invalid data conditions that cannot be remedied through data cleansing should be considered in defining trust and validation rules.
- Consider which external systems (including source systems) should be updated when data changes are made.
A spreadsheet format can be used to track the detailed analysis and it will provide the basis for other steps later in the process.
To perform part of this analysis, Cloud Data Quality could be used to identify, catalog, and profile the data. Identification can be used to assess the quality for each field and combination of fields, and to recognize good candidates for matching and filters. Cataloging allows field classification by their characteristics and profiling gives detailed statistics about the data.
Informatica’s Cloud platform enables connectivity to Salesforce and many other applications and systems, making Cloud Data Quality capabilities easy to leverage on the data typically used in Cloud Customer 360 projects.
Below is a screenshot of how the data is shown after profiling is performed on the Salesforce’s Account object:
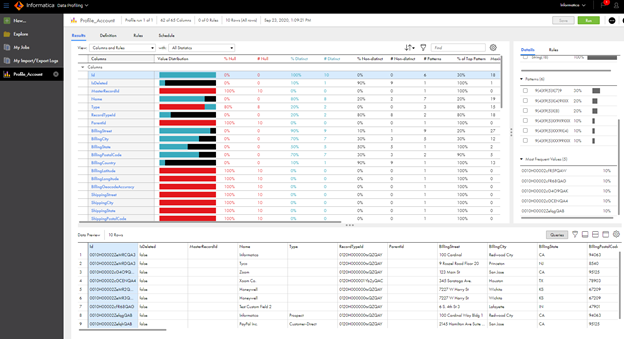
Step 2. Master Data Attributes
Cloud Customer 360 projects typically are focused on Customer master data within Salesforce, and therefore the attributes are common across most implementations: Account, Contact and Lead objects and the core fields therein: Name, Address, Postal Code, Country, Telephone, and Email.
Some data may have additional unique identifiers from external systems (e.g., ERP, MDM hub, Dunn & Bradstreet) already associated with all or part or some of the data, which can significantly help the matching process.
In this stage, once the basic Account, Contact and Lead object attributes have been identified, consideration should also be given to the external sources and transactional data that may be integrated with Salesforce in order to build out a single customer view
For example, the CRM system may contain Master data for attributes like Name, Postal Address, Country, Telephone and Email while an ERP system may provide Master data for Billing status, Amount, Ship-to address and Bill-to address fields.
This information can be layered onto the output from Step 1.
Step 3. Data Quality Audit
A data quality audit determines how fit the data is for its purpose and naturally follows from the outputs of Step 1. Data Quality Analysis and Step 2. Master Data Attributes.
This is an exercise to consider the technical output (e.g., field lists, master data items, data quality issues, and primary keys) against the business requirements and objectives to confirm the data can support and enable the business process.
This objective exercise should identify if the project can be successful with the data that is available or if transformations/translations, additional purchased data, scope changes, etc. are required to bring the data to a level of quality that will sustain the business process.
Step 4. Transformation/Translation Rules
A data transformation converts a set of data values from the data format of a source data system into the data format of a destination data system.
Ideally transformations and translations are developed according to the data quality analysis outputs and these are normally straightforward mapping exercises (e.g., England > United Kingdom). Data integration solutions can be used to develop complex decision logic to apply business rule changes, data standardization rules and data mappings.
Cloud Data Quality helps in data standardization efforts by using pre-built business rules and accelerators. With its capabilities for cleansing and standardizing, parsing, verifying addresses, and enriching data it also helps in the implementation of all of the rules generated from the analysis step.
Below is a screenshot of a mapping using cleansing and standardizing capabilities:
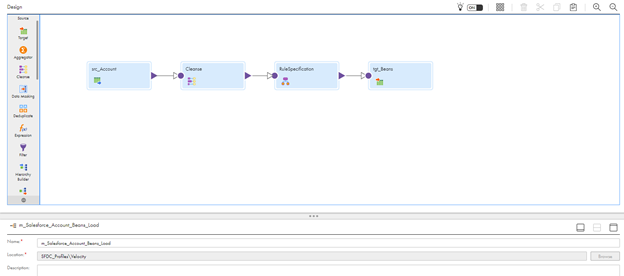
Step 5. Matching Rules
Once the outputs and actions from the earlier data quality stages are completed it is possible to start to define the data segmentation and matching rules in Cloud Customer 360.
Matching rules are determined by the data and business rules. Certain fields/attributes perform better than others and can be weighted accordingly.
Test/sample data that accurately represents production should be used to iteratively refine the matching rules and false positives. Known duplicates should be identified to provide boundaries and then the other results should be reviewed to identify the correct level of matching.
More information on matching and segmentation can be found in the Informatica Cloud Community.
Also refer to Cloud Customer 360 - Data Quality Analysis Template.