
-
Manage your Success Plans and Engagements, gain key insights into your implementation journey, and collaborate with your CSMsSuccessAccelerate your Purchase to Value by engaging with Informatica for Customer SuccessAll your Engagements at one place
-
A collaborative platform to connect and grow with like-minded Informaticans across the globeCommunitiesConnect and collaborate with Informatica experts and championsHave a question? Start a Discussion and get immediate answers you are looking forCustomer-organized groups that meet online and in-person. Join today to network, share ideas, and get tips on how to get the most out of Informatica
-
Troubleshooting documents, product guides, how to videos, best practices, and moreKnowledge CenterOne-stop self-service portal for solutions, FAQs, Whitepapers, How Tos, Videos, and moreVideo channel for step-by-step instructions to use our products, best practices, troubleshooting tips, and much moreInformation library of the latest product documents
-
Rich resources to help you leverage full capabilities of our productsLearnRole-based training programs for the best ROIGet certified on Informatica products. Free, Foundation, or ProfessionalFree and unlimited modules based on your expertise level and journeySelf-guided, intuitive experience platform for outcome-focused product capabilities and use cases
-
Library of content to help you leverage the best of Informatica productsResourcesMost popular webinars on product architecture, best practices, and moreProduct Availability Matrix statements of Informatica productsMonthly support newsletterInformatica Support Guide and Statements, Quick Start Guides, and Cloud Product Description ScheduleEnd of Life statements of Informatica productsMonitor the status of your Informatica services across regions
- Velocity
- Strategy
-
Solutions
- Stages
-
More
-
Manage your Success Plans and Engagements, gain key insights into your implementation journey, and collaborate with your CSMsManage your Success Plans and Engagements, gain key insights into your implementation journey, and collaborate with your CSMsAccelerate your Purchase to Value by engaging with Informatica for Customer SuccessAll your Engagements at one place
-
A collaborative platform to connect and grow with like-minded Informaticans across the globeA collaborative platform to connect and grow with like-minded Informaticans across the globeConnect and collaborate with Informatica experts and championsHave a question? Start a Discussion and get immediate answers you are looking forCustomer-organized groups that meet online and in-person. Join today to network, share ideas, and get tips on how to get the most out of Informatica
-
Troubleshooting documents, product guides, how to videos, best practices, and moreTroubleshooting documents, product guides, how to videos, best practices, and moreOne-stop self-service portal for solutions, FAQs, Whitepapers, How Tos, Videos, and moreVideo channel for step-by-step instructions to use our products, best practices, troubleshooting tips, and much moreInformation library of the latest product documents
-
Rich resources to help you leverage full capabilities of our productsRich resources to help you leverage full capabilities of our productsRole-based training programs for the best ROIGet certified on Informatica products. Free, Foundation, or ProfessionalFree and unlimited modules based on your expertise level and journeySelf-guided, intuitive experience platform for outcome-focused product capabilities and use cases
-
Library of content to help you leverage the best of Informatica productsLibrary of content to help you leverage the best of Informatica productsMost popular webinars on product architecture, best practices, and moreProduct Availability Matrix statements of Informatica productsMonthly support newsletterInformatica Support Guide and Statements, Quick Start Guides, and Cloud Product Description ScheduleEnd of Life statements of Informatica productsMonitor the status of your Informatica services across regions
-
Data Integration Load Traceability
Cloud Data Warehouse & Data Lake
Challenge
Load management is one of the major difficulties facing a data integration or data warehouse operations team. This Best Practice tries to answer the following questions:
- How can the team keep track of what has been loaded?
- What order should the data be loaded in?
- What happens when there is a load failure?
- How can bad data be removed and replaced?
- How can the source of data be identified?
- When it was loaded?
Description
Load management provides an architecture to allow all of the above questions to be answered with minimal operational effort.
Benefits of a Load Management Architecture
Data Lineage
The term Data Lineage is used to describe the ability to track data from its final resting place in the target back to its original source. This requires the tagging of every row of data in the target with an ID from the load management metadata model. This serves as a direct link between the actual data in the target and the original source data.
To give an example of the usefulness of this ID, a data warehouse or integration competency center operations team, or possibly end users, can, on inspection of any row of data in the target schema, link back to see when it was loaded, where it came from, any other metadata about the set it was loaded with, validation check results, number of other rows loaded at the same time, and so forth.
It is also possible to use this ID to link one row of data with all of the other rows loaded at the same time. This can be useful when a data issue is detected in one row and the operations team needs to see if the same error exists in all of the other rows. More than this, it is the ability to easily identify the source data for a specific row in the target, enabling the operations team to quickly identify where a data issue may lie.
It is often assumed that data issues are produced by the transformation processes executed as part of the target schema load. Using the source ID to link back the source data makes it easy to identify whether the issues were in the source data when it was first encountered by the target schema load processes or if those load processes caused the issue. This ability can save a huge amount of time, expense, and frustration -- particularly in the initial launch of any new subject areas.
Process Lineage
Tracking the order that data was actually processed in is often the key to resolving processing and data issues. Because choices are often made during the processing of data based on business rules and logic, the order and path of processing differs from one run to the next. Only by actually tracking these processes as they act upon the data can issue resolution be simplified.
Process Dependency Management
Having a metadata structure in place provides an environment to facilitate the application and maintenance of business dependency rules. Once a structure is in place that identifies every process, it becomes very simple to add the necessary metadata and validation processes required to ensure enforcement of the dependencies among processes. Such enforcement resolves many of the scheduling issues that operations teams typically faces.
Process dependency metadata needs to exist because it is often not possible to rely on the source systems to deliver the correct data at the correct time. Moreover, in some cases, transactions are split across multiple systems and must be loaded into the target schema in a specific order. This is usually difficult to manage because the various source systems have no way of coordinating the release of data to the target schema.
Robustness
Using load management metadata to control the loading process also offers two other big advantages, both of which fall under the heading of robustness because they allow for a degree of resilience to load failure.
Load Ordering
Load ordering is a set of processes that use the load management metadata to identify the order in which the source data should be loaded. This can be as simple as making sure the data is loaded in the sequence it arrives, or as complex as having a pre-defined load sequence planned in the metadata.
There are a number of techniques used to manage these processes. The most common is an automated process that generates a PowerCenter load list from flat files in a directory, then archives the files in that list after the load is complete. This process can use embedded data in file names or can read header records to identify the correct ordering of the data. Alternatively the correct order can be pre-defined in the load management metadata using load calendars.
Either way, load ordering should be employed in any data integration or data warehousing implementation because it allows the load process to be automatically paused when there is a load failure, and ensures that the data that has been put on hold is loaded in the correct order as soon as possible after a failure.
The essential part of the load management process is that it operates without human intervention, helping to make the system self healing!
Rollback
If there is a loading failure or a data issue in normal daily load operations, it is usually preferable to remove all of the data loaded as one set. Load management metadata allows the operations team to selectively roll back a specific set of source data, the data processed by a specific process, or a combination of both. This can be done using manual intervention or by a developed automated feature.
Simple Load Management Metadata Model
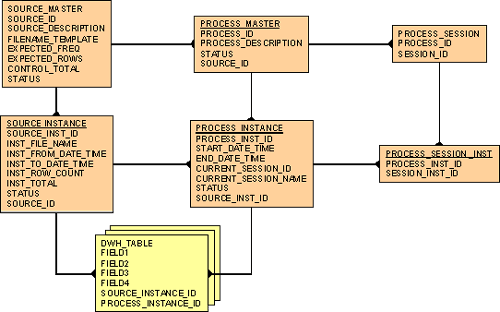
As you can see from the simple load management metadata model above, there are two sets of data linked to every transaction in the target tables. These represent the two major types of load management metadata:
- Source tracking
- Process tracking
Source Tracking
Source tracking looks at how the target schema validates and controls the loading of source data. The aim is to automate as much of the load processing as possible and track every load from the source through to the target schema.
Source Definitions
Most data integration projects use batch load operations for the majority of data loading. The sources for these come in a variety of forms, including flat file formats (ASCII, XML etc), relational databases, ERP systems, and legacy mainframe systems.
The first control point for the target schema is to maintain a definition of how each source is structured, as well as other validation parameters.
These definitions should be held in a Source Master table like the one shown in the data model above.
These definitions can and should be used to validate that the structure of the source data has not changed. A great example of this practice is the use of DTD files in the validation of XML feeds.
In the case of flat files, it is usual to hold details like:
- Header information (if any)
- How many columns
- Data types for each column
- Expected number of rows
For RDBMS sources, the Source Master record might hold the definition of the source tables or store the structure of the SQL statement used to extract the data (i.e., the SELECT, FROM and ORDER BY clauses).
These definitions can be used to manage and understand the initial validation of the source data structures. Quite simply, if the system is validating the source against a definition, there is an inherent control point at which problem notifications and recovery processes can be implemented. It’s better to catch a bad data structure than to start loading bad data.
Source Instances
A Source Instance table (as shown in the load management metadata model) is designed to hold one record for each separate set of data of a specific source type being loaded. It should have a direct key link back to the Source Master table which defines its type.
The various source types may need slightly different source instance metadata to enable optimal control over each individual load.
Unlike the source definitions, this metadata will change every time a new extract and load is performed. In the case of flat files, this would be a new file name and possibly date / time information from its header record. In the case of relational data, it would be the selection criteria (i.e., the SQL WHERE clause) used for each specific extract, and the date and time it was executed.
This metadata needs to be stored in the source tracking tables so that the operations team can identify a specific set of source data if the need arises. This need may arise if the data needs to be removed and reloaded after an error has been spotted in the target schema.
Process Tracking
Process tracking describes the use of load management metadata to track and control the loading processes rather than the specific data sets themselves. There can often be many load processes acting upon a single source instance set of data.
While it is not always necessary to be able to identify when each individual process completes, it is very beneficial to know when a set of sessions that move data from one stage to the next has completed. Not all sessions are tracked this way because, in most cases, the individual processes are simply storing data into temporary tables that will be flushed at a later date. Since load management process IDs are intended to track back from a record in the target schema to the process used to load it, it only makes sense to generate a new process ID if the data is being stored permanently in one of the major staging areas.
Process Definition
Process definition metadata is held in the Process Master table (as shown in the load management metadata model ). This, in its basic form, holds a description of the process and its overall status. It can also be extended, with the introduction of other tables, to reflect any dependencies among processes, as well as processing holidays.
Process Instances
A process instance is represented by an individual row in the load management metadata Process Instance table. This represents each instance of a load process that is actually run. This holds metadata about when the process started and stopped, as well as its current status. Most importantly, this table allocates a unique ID to each instance.
The unique ID allocated in the process instance table is used to tag every row of source data. This ID is then stored with each row of data in the target table.
Integrating Source and Process Tracking
Integrating source and process tracking can produce an extremely powerful investigative and control tool for the administrators of data warehouses and integrated schemas. This is achieved by simply linking every process ID with the source instance ID of the source it is processing. This requires that a write-back facility be built into every process to update its process instance record with the ID of the source instance being processed.
The effect is that there is a one to one/many relationship between the source instance table and the process instance table containing several rows for each set of source data loaded into a target schema. For example, in a data warehousing project, a row for loading the extract into a staging area, a row for the move from the staging area to an ODS, and a final row for the move from the ODS to the warehouse.
Integrated Load Management Flow Diagram
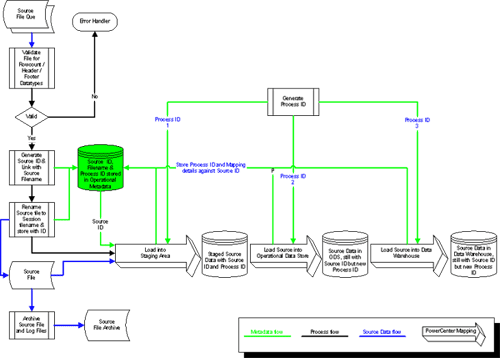
Tracking Transactions
This is the simplest data to track since it is loaded incrementally and not updated. This means that the process and source tracking discussed earlier in this document can be applied as is.
Tracking Reference Data
This task is complicated by the fact that reference data, by its nature, is not static. This means that if you simply update the data in a row any time there is a change, there is no way that the change can be backed out using the load management practice described earlier. Instead, Informatica recommends always using slowly changing dimension processing on every reference data and dimension table to accomplish source and process tracking. Updating the reference data as a ‘slowly changing table’ retains the previous versions of updated records, thus allowing any changes to be backed out.
Tracking Aggregations
Aggregation also causes additional complexity for load management because the resulting aggregate row very often contains the aggregation across many source data sets. As with reference data, this means that the aggregated row cannot be backed out in the same way as transactions.
This problem is managed by treating the source of the aggregate as if it was an original source. This means that rather than trying to track the original source, the load management metadata only tracks back to the transactions in the target that have been aggregated. So, the mechanism is the same as used for transactions but the resulting load management metadata only tracks back from the aggregate to the fact table in the target schema.