
-
Manage your Success Plans and Engagements, gain key insights into your implementation journey, and collaborate with your CSMsSuccessAccelerate your Purchase to Value engaging with Informatica Architects for Customer SuccessAll your Engagements at one place
-
A collaborative platform to connect and grow with like-minded Informaticans across the globeCommunitiesConnect and collaborate with Informatica experts and championsHave a question? Start a Discussion and get immediate answers you are looking forCustomer-organized groups that meet online and in-person. Join today to network, share ideas, and get tips on how to get the most out of Informatica
-
Troubleshooting documents, product guides, how to videos, best practices, and moreKnowledge CenterOne-stop self-service portal for solutions, FAQs, Whitepapers, How Tos, Videos, and moreVideo channel for step-by-step instructions to use our products, best practices, troubleshooting tips, and much moreInformation library of the latest product documentsBest practices and use cases from the Implementation team
-
Rich resources to help you leverage full capabilities of our productsLearnRole-based training programs for the best ROIGet certified on Informatica products. Free, Foundation, or ProfessionalFree and unlimited modules based on your expertise level and journeySelf-guided, intuitive experience platform for outcome-focused product capabilities and use cases
-
Library of content to help you leverage the best of Informatica productsResourcesMost popular webinars on product architecture, best practices, and moreProduct Availability Matrix statements of Informatica productsMonthly support newsletterInformatica Support Guide and Statements, Quick Start Guides, and Cloud Product Description ScheduleEnd of Life statements of Informatica products
- Success Portal
- Learning Path
- Cloud Data Integration & Engineering
Kickstart your IDMC Journey
Before you start this course, it is recommended to complete the following prerequisites, which consist of three key modules:
- Know Your IDMC: Gain a clear understanding of IDMC principles.
- Create Your Team: Easily navigate adding a user in IDMC, explore system-defined and custom roles.
- Run Your First Job: Get hands-on experience on foundational tasks for effective data integration in IDMC
Completing these modules will prepare you to engage with the main course material confidently.
Course Overview
Start your learning journey in data integration and engineering by mastering the art of presenting Informatica’s new messaging, use cases, industry-leading product innovations, and customer case studies to your customers.
Why Best?
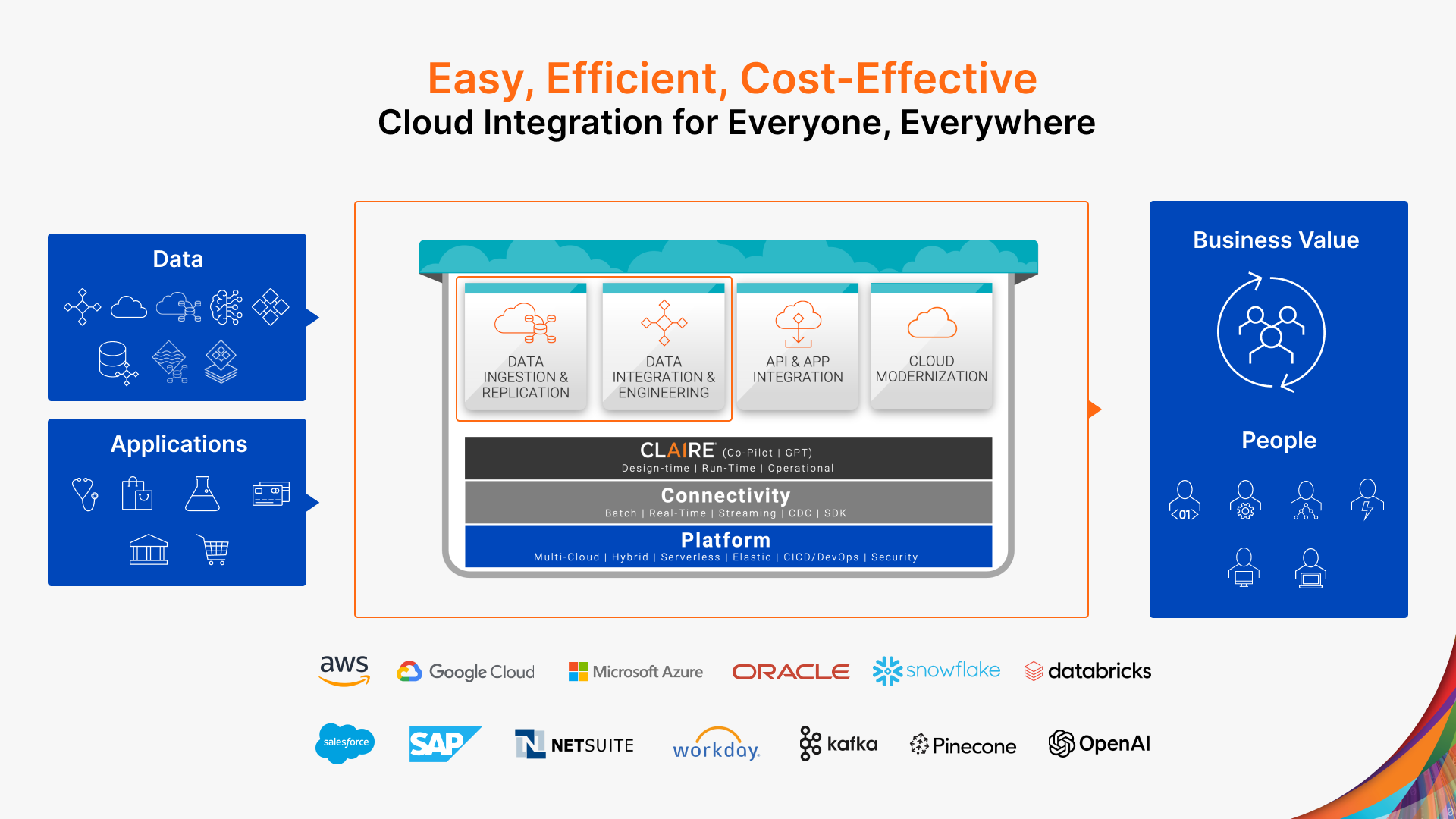
Informatica is the only vendor to provide an end-to-end data integration and engineering solution at an enterprise scale that is easy, efficient, and cost-effective for everyone (all user persona) and everywhere (multi-vendor, multi-cloud, hybrid). Informatica is the only data integration and engineering vendor to:
- Support end-to-end data integration and engineering use cases
- Support all integration patterns such as data replication, ETL, ELT, Reverse ETL, etc.
- Infuse intelligence and automation into the data integration process.
Solution Capabilities
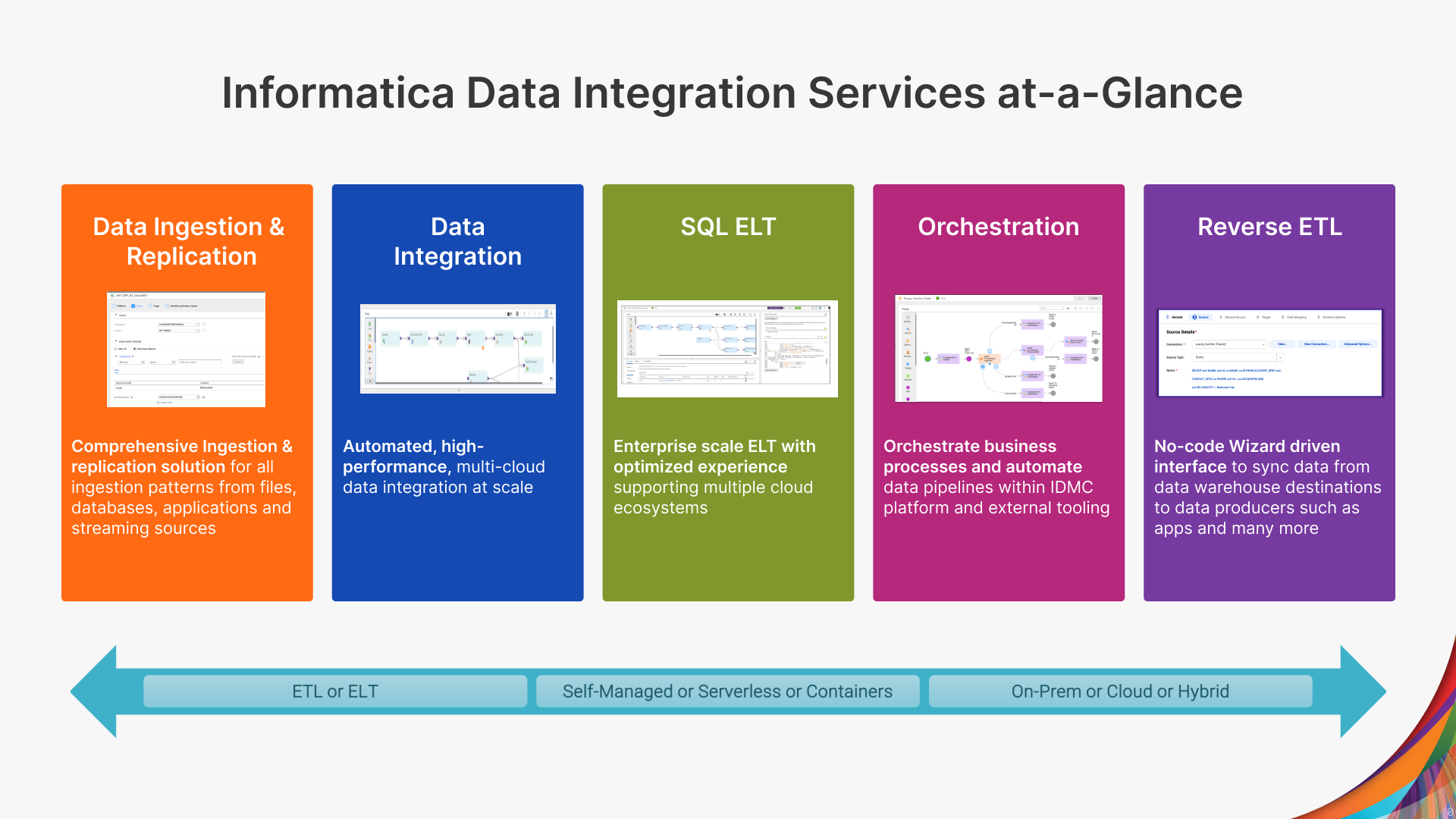
Informatica provides the following data integration and engineering services and capabilities as part of Informatica’s Intelligent Data Management Cloud (IDMC).
- Data Integration: Automated, high-performance, multi-cloud data integration at scale
- Data Ingestion and Replication: Comprehensive ingestion & replication solution for all ingestion patterns from files, databases, CDC, applications, and streaming sources
- SQL ELT: Enterprise scale ELT with optimized experience supporting multiple cloud ecosystems
- Orchestration: Orchestrate business processes and automate data pipelines within the IDMC platform and external tooling
- Reverse ETL: No-code wizard-driven interface to sync data from data warehouse destinations to data producers such as apps and many more
- INFACore: Open, embeddable, and extensible intelligent headless data management taking power of IDMC to various developer interfaces
- ModelServe: Simple, easy-to-use, wizard-driven approach for data scientists and ML engineers to deploy and operationalize any AI/ML models at scale
- Data Validation: Wizard-based integrated validation capability for improved confidence in data pipelines
- CDI-Free: Free ingestion/replication and transformation offering for departmental users.

Customer Success Stories
1. An HR software company used our AI-powered intelligence and automation to cut data wrangling time by 90% and shorten their reporting cycle from months to weeks. This boosted data engineer productivity, ensuring timely data availability for effective AI consumption and smarter organizational decision-making.
2. The world’s leading Spanish-language media company leveraged our AI-powered IDMC to slash development efforts by 95% and accelerate time to market. This initiative fosters a data-driven culture, utilizing robust, high-quality data services for AI consumption, thereby enhancing efficiency and affirming its industry-leading position.
3. A pet product company streamlined data integration between its Snowflake data warehouse and other assets using a new platform, which also consolidates costs under a flexible license. This facilitated quicker workflows and cost savings, with seamless automation of workflow mappings across various domains and data sources.


