
-
Manage your Success Plans and Engagements, gain key insights into your implementation journey, and collaborate with your CSMsSuccessAccelerate your Purchase to Value by engaging with Informatica for Customer SuccessAll your Engagements at one place
-
A collaborative platform to connect and grow with like-minded Informaticans across the globeCommunitiesConnect and collaborate with Informatica experts and championsHave a question? Start a Discussion and get immediate answers you are looking forCustomer-organized groups that meet online and in-person. Join today to network, share ideas, and get tips on how to get the most out of Informatica
-
Troubleshooting documents, product guides, how to videos, best practices, and moreKnowledge CenterOne-stop self-service portal for solutions, FAQs, Whitepapers, How Tos, Videos, and moreVideo channel for step-by-step instructions to use our products, best practices, troubleshooting tips, and much moreInformation library of the latest product documents
-
Rich resources to help you leverage full capabilities of our productsLearnRole-based training programs for the best ROIGet certified on Informatica products. Free, Foundation, or ProfessionalFree and unlimited modules based on your expertise level and journeySelf-guided, intuitive experience platform for outcome-focused product capabilities and use cases
-
Library of content to help you leverage the best of Informatica productsResourcesMost popular webinars on product architecture, best practices, and moreProduct Availability Matrix statements of Informatica productsMonthly support newsletterInformatica Support Guide and Statements, Quick Start Guides, and Cloud Product Description ScheduleEnd of Life statements of Informatica productsMonitor the status of your Informatica services across regions
- Success Portal
- Learning Path
- Cloud Data Ingestion and Replication
- Database Ingestion
Database Ingestion and Replication is part of the Intelligent Data Management Cloud (IDMC) Cloud Data Ingestion and Replication service.
It allows large-scale data ingestion from common relational databases to various targets, including cloud-based and big-data targets.
This feature requires a separate license and offers a user-friendly interface for setting up, deploying, running, and monitoring ingestion jobs.
There are three types of load operations that Database Ingestion and Replication can perform:

- Initial load: Transfers data from a source to a target at a single point in time. This is useful for migrating data to a cloud-based system, materializing targets for incremental updates, or adding data to data lakes or warehouses.
- Incremental load: Continuously updates the target with data changes since the last run or from a specified start point. This is ideal for keeping reporting, analytics, and online machine learning systems current.
- Initial and incremental load: Begins with an initial load and then switches to continuous incremental updates to the same source tables giving flexibility to perform both initial and incremental load in the same job.
The service automatically maps the source to target tables and fields based on name matching, with options to customize target table names through defined rules.
- Ingestion and replication from DB and Mainframe sources with no footprint on the source database
- Simple and easy way to build and manage ingestion and replication pipeline with wizard-driven interface
- No breakage of pipelines in case of schema changes at the source
Easy:
- Easy 4-step wizard for data engineers to replicate and ingest bulk and CDC data from databases, and mainframes.
- Out of the connectivity to relational DBs and mainframes including DB2 z/OS.
Efficient:
- High-performant bulk load from various sources including relational DB and Mainframes.
- Efficient and no intrusive CDC capture from relational and mainframes.
- Performant way of ingesting and applying CDC onto CDW, CDL, and messaging systems.
Cost-Effective:
- Ingest tens of thousands of databases & applications along with CDC in minutes.
- Automatic schema drift handling– for source schema changes.
Database Ingestion and Replication can be used to address multiple inclusions. Some of the most common use cases include:
- Offline reporting: Move user reporting activity from a mission-critical production database system to a separate reporting system to avoid degrading database performance.
- Machine Learning and Generative AI: Help build data warehouses and data lakes by transferring data from multiple databases, including on-premises databases. Keep them current by continuously replicating data after the initial load. This data warehouse or data lake can then be used to power enterprise Machine Learning and Generative AI flows.
- Migration to cloud-based systems: Migrate data from on-premises database systems to cloud-based systems.
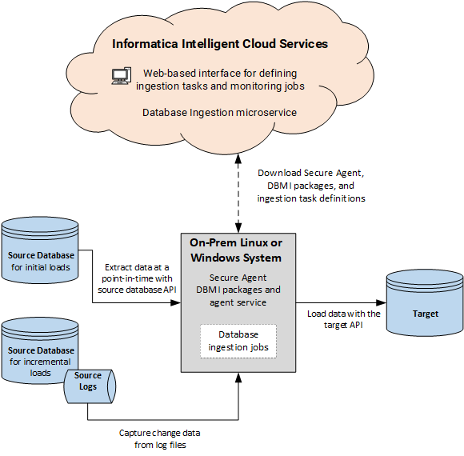
Database Ingestion and Replication operates on a Secure Agent, which must be installed on a Linux or Windows machine. Once the Secure Agent is started for the first time, the Database Ingestion and Replication agent and packages are installed locally, allowing for the configuration, deployment, and monitoring of database ingestion tasks and jobs through the Intelligent Data Management Cloud (IDMC) Web-based interface.
Deploying a task creates an executable job on the Secure Agent system. When a database ingestion job is run, task metadata is sent from the IDMC Cloud instance to the Secure Agent, which processes the data accordingly.
Change data capture (CDC) allows users to detect and manage incremental changes at the data source. Data consumers can absorb changes in real time with minimal impact on the data source or the transport system between the data source and the consumer. CDC captures changes from database transaction logs which are then published to a destination such as a cloud data lake, cloud data warehouse, or message hub.
The benefits of CDC include:
- Greater efficiency: With CDC, only data that has changed is synchronized which saves time and enhances the accuracy of data and analytics
- Lower impact on production databases: CDC has minimal impact on the source. This facilitates high-volume data transfers to the analytics target.
- Improved time to value and lower TCO: CDC helps build data pipelines faster, saving time for data engineers and architects thereby reducing total cost of ownership (TCO).
Types of CDC
- Timestamp-based CDC: Leverages a table timestamp column and retrieves only those rows that have changed since the data was last extracted. This is the simplest method to extract incremental data with CDC but can slow down production performance by consuming source CPU cycles
- Trigger-based CDC: It defines triggers that fire before or after INSERT, UPDATE, or DELETE commands and are used to create change logs in a change table. This increases processing overheads and slows down source production operations.
- Log-based CDC: Transactional databases store all changes in a transaction log that helps the database to recover in the event of a crash. With log-based CDC, new database transactions (inserts, updates, and deletes) are read from source databases’ transactions without making application-level changes and without having to scan operational tables.
Benefits of Log-based CDC:
- This is the most preferred and fastest CDC method
- It is non-intrusive and least disruptive for production database sources
- No overhead on the database server performance
Database ingestion supports a wide variety of sources and targets. These include database sources such as SQL Server, SAP Hana, and mainframe sources like Db2, etc. The supported targets include a wide range of data warehouses, data lakes, and event queues. Some of the famed supported targets include Amazon Redshift, Amazon S3, Apache Kafka, Microsoft SQL Server, Databricks Delta, Google BigQuery, Microsoft Fabric OneLake, and Snowflake among others.
See the full list and the load types supported for all the targets below:


A dedicated CDC Staging Task reads source change data once and writes it to a common storage layer for multiple downstream apply jobs, enhancing performance and scalability. The data is stored in Parquet format within Iceberg tables.
You can define a CDC staging group that includes multiple database ingestion and replication tasks - either incremental loads or combined initial and incremental loads - from sources such as Db2 for i, Db2 for LUW, Db2 for z/OS, Oracle, Microsoft SQL Server, or SAP HANA. Note that Db2 for LUW, Oracle, and SAP HANA sources must use the Log-based CDC method.
When staging groups are enabled, the CDC Staging Task reads data from the source database in a single pass and writes it to common storage. The associated apply tasks then read from this common storage to apply data to different targets. This approach improves CDC performance and scalability by reading source logs only once, rather than multiple times by each apply job. Additionally, if you use a Secure Agent group, apply jobs can run on different agents within the same group.
Note: To enable this feature, please contact Informatica Global Customer Support. They will activate the cdir.cdc.group.enabled flag for your organization.
Common Storage Types Used by CDC Staging Task:
For Db2 for i, Db2 for LUW, Db2 for z/OS, Oracle, and Microsoft SQL Server sources, the CDC Staging Task writes data to cloud Iceberg storage. Supported cloud storage options include Amazon S3, Google Cloud Storage, and Microsoft Azure Data Lake Storage Gen2 (using Shared Key Authentication). By default, staged data is retained for 14 days, but this retention period can be extended up to 365 days.
For SAP HANA sources, the CDC Staging Task writes data to an SAP HANA or Oracle cache, as specified in the SAP HANA Database Ingestion connection properties. Each CDC Staging Task requires its own cache database and connection. The Secure Agent stages data to this cache, and once full records are available, writes the data to the target. By default, cached data is compacted after 14 days but not deleted. This retention period can be adjusted using the Log Clear connection property.
Before configuring a Database Ingestion task for initial, incremental, or combined initial and incremental operations, you need to prepare the source databases and targets to ensure they are ready for the Database Ingestion and Replication task and to avoid any unexpected results. Informatica Database Ingestion supports a wide variety of sources and targets. Detailed steps to prepare these sources and targets for a database ingestion job can be found below.


Configuration of a Database Ingestion task requires the following steps:
- Preliminary Checks
- Starting the ingestion and replication task wizard
- Configuring Target Information
- Configuring Source Information
- Configuring the Runtime Options
Click on the below resources to get detailed information about how to configure the Database Ingestion task for your choice of source and targets:





Working with Oracle as a Source for your DB Ingestion Job with incremental or combined load?
The methods for accessing Oracle redo logs for Change Data Capture (CDC) processing in Database ingestion and replication jobs, specifically incremental load and combined initial and incremental load jobs, can vary based on your specific environment and requirements. Here are some alternative ways:
- Direct Log Access: Jobs can directly access the physical Oracle redo logs on the on-premises source system to read change data. This method can provide the best performance if you store the logs on a solid-state disk (SSD).
- NFS-Mounted Logs: Jobs can access Oracle database logs from a shared disk using a Network File Sharing (NFS) mount or another method such as Network Attached Storage (NAS) or clustered storage.
- ASM-Managed Logs: Jobs can access Oracle redo logs that are stored in an Oracle Automatic Storage Management (ASM) system. To read change data from the ASM-managed redo logs, the ASM user must have SYSASM or SYSDBA authority on the ASM instance.
- ASM-Managed Logs with a Staging Directory: Jobs can access ASM-managed redo logs from a staging directory in the ASM environment. This method can provide faster access to the log files and reduce I/O on the ASM system.
- BFILE Access to Logs in the Oracle Server File System by Using Directory Objects: On an on-premises Oracle source system, you can configure Database Ingestion and Replication to read online and archived redo logs from the local Oracle server file system by using Oracle directory objects with BFILE locators.
Please note that the specific method to be used depends on your environment and requirements. Reference videos below:




To address challenges in target systems such as high overhead, performance degradation from unoptimized data access, increased processing time, and slower data replication, CDIR offers a Row Filter option. This feature filters rows per table or object during initial, incremental, and combined loads, providing significant benefits.
Row Filter in CDIR:
- Enhances performance and scalability by reducing overhead on the target system.
- Minimizes additional processing by transferring only the required and clean data to the target.
- Optimizes ingestion and replication processes for faster data replication.
- Offers flexibility to define filter conditions using either Basic or Advanced types, with validation options available during task configuration.
When working with relational sources and targets like Amazon Redshift, Databricks, Google BigQuery, Microsoft Azure Synapse Analytics, Microsoft SQL Server, Oracle, PostgreSQL, and Snowflake, data-type mappings play a crucial role. By default, Database Ingestion and Replication automatically apply standard mappings to create target tables seamlessly.
Key Highlights:
- Default Mappings: Predefined data-type mappings ensure smooth generation of target tables.
- Customization: You can tweak the default mappings by configuring custom data-type rules to better suit your needs.
- Unsupported Data Types: If a source data type isn’t listed, it may not be extractable or applicable to a target.
Next Steps:
For a deeper dive, explore how to customize data-type mappings to optimize your configurations by referring to the KB below:


Schema Drift occurs when changes in the source schema need to be automatically detected and managed on the target during data ingestion and replication. Database Ingestion and Replication allows you to configure how these changes are handled to ensure seamless data flow.
Key Highlights:
- Supported Schema Changes: Automatically detects and manages adding, modifying, or dropping columns.
- Configurable Options: During task setup, you can choose to ignore changes, replicate them, or stop the task upon detecting a change.
- Default Behavior: Schema change handling varies by target type to maintain compatibility and stability.
Important Considerations:
- Unsupported schema changes on the target cause the replication job to fail with an error.
- Changes to primary or unique key constraints are not replicated; target tables must be resynchronized in such cases.
- For Oracle and SQL Server sources, new columns are assumed to be added at the end of the table. Adding columns elsewhere may cause misinterpretation and alerts.
Pro Tips: Apply schema changes one at a time, followed by at least one DML operation, to ensure accurate detection.
For detailed configurations, refer to Configuring Schedule and Runtime Options in the product documentation.
There are some best practices to follow when handling schema drift in Database Ingestion jobs:
Overriding schema drift options when resuming a database ingestion and replication job: You can override the schema drift options when you resume a database ingestion and replication job that is in the Stopped, Aborted, or Failed state. The overrides affect only those tables that are currently in the Error state because of the Stop Table or Stop Job Schema Drift option. Use the overrides to correct or resolve these errors. You can override schema drift options and resume an incremental load job or a combined initial and incremental load job from the All Jobs tab on the Data Ingestion and Replication page in Operational Insights.
Schema Drift Options: There are several schema drift options you can select when resuming a job with an override. Each option has a different impact on how the job handles schema changes, so choose the one that best suits your needs.
Here are the different schema drift options and their impacts when resuming a database ingestion and replication job:
- Ignore: This option does not replicate DDL changes that occur on the source database to the target.
- Stop Table: This option stops processing the source table on which the DDL change occurred. The job cannot retrieve the data changes that occurred on the source table after the job stopped processing it. Consequently, data loss might occur on the target. To avoid data loss, you will need to resynchronize the source and target objects that the job stopped processing.
- Resync: This option resynchronizes the target tables with the latest source table definitions, including any DDL changes that the schema drift ignored. Use this option for tables that the job stopped processing because of the Stop Table setting for a Schema Drift option. This option is available only for combined initial and incremental load jobs.
- Resync (refresh): For database ingestion and replication combined load jobs that have an Oracle or SQL Server source, use this option to resynchronize the target tables with the latest source table definitions, including any DDL changes that schema drift ignored. After the target tables are refreshed, the structure of the source and target tables match. This option mimics the behavior of the Resync option.
- Resync (retain): For database ingestion and replication combined load jobs that have an Oracle or SQL Server source, use this option to resynchronize the same columns that have been processed for CDC, retaining the current structure of the source and target tables. No checks for changes to the source or target table definitions are performed. If source DDL changes affect the source table structure, those changes are not processed.
- Replicate: This option allows the database ingestion and replication job to replicate the DDL change to the target. If you specify the Replicate option for Rename Column operations on Microsoft Azure Synapse Analytics targets, the job will end with an error.
In the process of Database Ingestion and Replication, the Apply Mode is a crucial setting that determines how changes from the source are applied to the target. Here's an explanation of the three Apply Modes:
- Standard Mode: Think of this as a smart mode that optimizes how changes are applied to the target. It collects all changes in one cycle and merges them into fewer SQL statements. For instance, if a row in the source is updated and then deleted, no row is applied to the target. If there are multiple updates on the same field, only the last update is applied to the target.
- Soft Deletes Mode: This mode doesn't remove deleted rows from the database. Instead, it marks them as deleted by placing a "D" in the INFA_OPERATION_TYPE column against the deleted record. However, it's important to remember not to update the primary key in a source table when using this mode, as it can lead to data corruption on the target.
- Audit Mode: This mode creates an audit trail of every change made on the source tables. Each change on a source table is written to the target table along with selected audit columns. These columns contain metadata about the change like the type of operation, time, owner, transaction ID, and more. However, Audit modes are not supported for Query-based CDC.

To set the Apply Mode, you would do it on the Target page of the task wizard when configuring the database ingestion and replication task. For more detailed steps, you can refer to the Informatica documentation.
Remember, these modes are designed to give you control over how changes are replicated, so choose the one that best suits your needs.
Deploying a Database Ingestion task
After defining a database ingestion task and saving it, you can deploy the task to create an executable job instance on the on-premises system that contains the Secure Agent and the Database Ingestion agent service and packages. You must deploy the task before you can run the job. The deployment process also validates the task definition. If the deployment process fails, the job status switches to Failed. You can then Undeploy the job and review the error logs from the Operational Insights page. After you resolve the problem, deploy the task again from the database ingestion and replication task wizard.
Running a Database Ingestion task
You can run a deployed database ingestion and replication job from one of the monitoring interfaces, or when you create a database ingestion and replication initial load task, you can specify a schedule for running the job instances associated with a task. Please refer to the articles below:


For step-by-step guidance on the most common replication scenarios, choose one of the links below that best fits your needs.
Implementing Oracle to Snowflake Synchronization using Cloud Mass Ingestion Databases

Ingesting Db2 for I Change Data into Snowflake with Cloud Mass Ingestion Databases

Ingesting Db2 for z/OS Change Data into Snowflake with Cloud Mass Ingestion Databases

Ingesting SQL Server Data & CDC changes into Amazon Redshift with Mass Ingestion Databases

Superpipe
For users with Snowflake Data Cloud Targets, moving large-scale data involves computation challenges and could impact performance for high-scale/low-latency processing. This creates complexities in connecting data sources for analytics in Snowflake Data Cloud. Superpipe is a joint innovation between Informatica and Snowflake which enables customers to, replicate and stream both initial and incremental data changes up to 3.5x faster than standard CDC approaches.


Superpipe leverages Snowflake’s Snowpipe streaming and Deferred Merge for high-performance real-time ingestion into Snowflake Data Cloud. This ensures real-time data view is always available regardless of CDC’s deferred merge interval set. This change table view along with view created on the final target table lets users always have a near-real-time view. Deferred merge applies changes on a periodic basis instead of transactional boundaries which results in up to 40% lesser Snowflake credit consumption.
Find helpful resources below:

Database Ingestion Log Collection Tool in Windows.
Explains how to use the diagnostic tool to collect the database ingestion logs on Windows. It aids effective troubleshooting by capturing errors and performance details for faster issue resolution.
Troubleshooting Database Ingestion Service Failures.
Guides users through identifying and resolving common issues that cause database ingestion service failures. It covers diagnosing connection problems, reviewing log files for error messages, checking configuration settings, and addressing resource or permission issues.


CDIR Job Failures with Supplemental Logging Errors.
Provides solutions to address CDIR job failures caused by missing or incorrect supplemental logging configurations. Following these steps helps ensure successful CDIR job execution and reliable data ingestion.
How to Troubleshoot CDIR Job Failure with the “OCI path not set” Error.
Demonstrates how to resolve CDIR job failures resulting from an unset or incorrect OCI path. Following these steps helps restore connectivity and allows CDIR jobs to run successfully.


How to Troubleshoot CDIR Job Failure with the “SCN not in the valid SCN range” error.
It covers steps to fix CDIR job failures triggered by an invalid or out-of-range SCN value. The guide also includes tips to prevent SCN-related errors by maintaining proper redo log and archival configurations, ensuring continuous and accurate data ingestion.
How to apply Custom properties at the global level in DBMI.
Details the process of configuring and applying custom properties at the global level in Database Ingestion Jobs. Following this approach helps streamline configuration management, improve job consistency, and optimize ingestion performance at scale.

Stay informed about upcoming expert-led webinars to deepen your knowledge of cloud data ingestion and replication, enabling seamless and efficient data movement - View upcoming webinars

Best Practices
Unlock the Power of Informatica Cloud: FAQs, Use-cases, and Best Practices
 Apr 23, 2024
Apr 23, 2024
 8:00 AM PT
8:00 AM PT

Product Feature
Accelerate your Analytics Journey on Snowflake with Informatica Superpipe
Apr 09, 2024
8:00 AM PT

Best Practices
How Cloud Mass Ingestion (CMI) Helps to Build Real-Time Analytics Layer in Cloud
Jan 09, 2024
8:00 AM PT

Product Overview
Ingest and Replicate Applications Data in Minutes
Jan 24, 2023
8:00 AM PST
Product Feature
Streaming Data Ingestion and Replication for Real-Time Analytics
Jan 17, 2023
8:00 AM PST